? Pas très intéressant.
Ainsi pourrait penser une personne moyenne travaillant avec des SIG ou des visualisations de données. Je dois admettre que les bases de données ne sont pas la chose la plus sexy au monde (désolé les DBA), mais si vous prétendez (ou visez) faire de l’analyse ou de la visualisation avec des données (spatiales) de manière plus sérieuse, vous ne devriez certainement pas les ignorer. J’espère que cet article de blog pourra vous donner une idée des avantages que l’utilisation efficace des bases de données spatiales pourrait vous offrir.
Les termes hype vont et viennent et il y avait un grand battage médiatique autour du big Data il y a encore quelques années, mais cela s’estompe lentement. Eh bien, les données sont toujours grandes et en fait, elles sont plus grandes que jamais. La taille des fichiers augmente et dans la « science des données » et les géosciences, les gens doivent traiter des données qui peuvent facilement se situer dans la gamme des gigaoctets. Plus les données sont volumineuses, plus nous devons accorder d’attention à la façon dont nous les stockons et les analysons.
C’est là qu’une base de données entre en jeu.
Dans le développement de logiciels, travailler avec des bases de données est un must. Mais pour les personnes d’autres sous-domaines de l’informatique (comme les SIG), les avantages d’une base de données peuvent ne pas toujours être aussi évidents. Bien sûr, les gens ont tendance à utiliser les outils qui leur sont les plus familiers, bien que ce ne soit pas le moyen le plus efficace d’atteindre leurs objectifs. Mais parfois, sortir de votre zone de confort peut vraiment vous apporter de gros avantages. J’ai moi-même réalisé lentement le potentiel du SQL spatial.

Cet article de blog est principalement destiné aux personnes qui travaillent avec des données géospatiales, mais qui n’ont pas touché PostGIS, ou peut-être n’en ont même pas entendu parler. Je ne vais pas voir comment installer PostgreSQL / PostGIS, mais plutôt essayer de vous donner un aperçu de ce que c’est et à quoi sert-il.
Mon flux de travail et mes exemples se concentrent principalement sur la combinaison QGIS + PostGIS, mais vous devez noter que vous pouvez également travailler uniquement avec PostGIS, votre propre code ou avec d’autres clients SIG.
Poste what quoi ?
Déjà pendant mes études SIG, j’avais entendu plusieurs fois l’expression « PostGIS est une extension spatiale de Postgres ». Ça ne voulait pas dire que j’avais une idée de ce que ça veut dire. Je n’avais aucune idée de ce qu’est Postgres, encore moins d’une extension spatiale.
Essayons de le freiner aussi simplement que possible.
Certaines personnes pourraient me détester pour cette comparaison mais je prendrai le risque: si vous n’avez jamais travaillé avec des bases de données, vous pouvez considérer les tables de base de données comme des feuilles Excel massives. Mais une feuille Excel intelligente massive d’où vous pouvez en une milliseconde savoir quelle est la valeur sur la troisième colonne du numéro de ligne 433 285. Et au lieu d’écrire des fonctions à l’intérieur de la feuille dans une seule cellule, vous les écrivez dans votre fenêtre de commande SQL. Donc, un endroit pour stocker des données et d’où vous pouvez les extraire efficacement.
PostGIS est un extendeur de base de données spatiales libre et disponible gratuitement pour le système de gestion de base de données PostgreSQL (alias SGBD). PostgreSQL (alias Postgres) est donc LA base de données et PostGIS est comme un add-on à cette base de données. La dernière version de PostGIS est désormais fournie avec PostgreSQL.
En un mot, PostGIS ajoute des fonctions spatiales telles que les types de données de géométrie de distance, d’aire, d’union, d’intersection et de spécialité à PostgreSQL Tm.Les bases de données spatiales stockent et manipulent des objets spatiaux comme tout autre objet de la base de données.
Ainsi, dans une base de données normale, vous stockez des données de différents types (numériques, texte, horodatages, images.) et si nécessaire, vous pouvez les interroger (les récupérer) pour répondre aux questions avec vos données. Les questions peuvent porter sur « combien de personnes se sont connectées à votre site Web » ou « combien de transactions ont été effectuées dans une boutique en ligne ». Les fonctions spatiales peuvent à la place répondre à des questions telles que « quelle est la proximité du magasin le plus proche », « ce point est-il à l’intérieur de cette zone » ou « quelle est la taille de ce pays ».
Les données sont donc stockées en lignes et en colonnes. Comme PostGIS est une base de données spatiale, les données ont également une colonne de géométrie avec des données dans un système de coordonnées spécifique défini par l’identifiant de référence spatiale (SRID). Mais rappelez-vous que bien que vous utilisiez PostGIS principalement pour des données spatiales, il est également possible d’y stocker des données non spatiales, car il possède toujours toutes les fonctionnalités d’une base de données PostgreSQL normale!
L’excellente intro Boundless PostGIS introduit trois concepts de base qui associent des données spatiales à une base de données. Combinés, ils offrent une structure flexible pour des performances et une analyse optimisées.
- Types de données spatiales tels que point, ligne et polygone. Familier à la plupart des personnes travaillant avec des données spatiales ;
- L’indexation spatiale multidimensionnelle est utilisée pour un traitement efficace des opérations spatiales ;
- Les fonctions spatiales, posées en SQL, servent à interroger des propriétés et des relations spatiales.
SQL, ou « Langage de requête structuré », est un moyen de poser des questions et de mettre à jour des données dans des bases de données relationnelles. Une requête select (que vous utilisez pour poser les questions) est généralement une commande de la forme suivante
SELECT some_columns FROM some_data_source WHERE some_condition;
Les fonctions spécifiques à PostGIS sont généralement sous la forme de ST_functionName.
Vous écrivez ces commandes sur la ligne de commande après vous être connecté à votre base de données ou dans votre outil graphique de base de données (par exemple pgAdmin ou QGIS DB Manager). Donc oui, SQL vous oblige à écrire vraiment quelque chose. Un clic droit peut être sous-estimé en général, mais pour quelqu’un qui n’écrit aucun code, SQL est une bonne première étape pour écrire vos propres commandes et peut-être plus tard du code.
Il existe également d’autres bases de données spatiales en plus de PostGIS. SQL Server Spatial, ESRI ArcSDE, Oracle Spatial et GeoMesa sont quelques autres options pour gérer et analyser les données spatiales. Mais on dit que PostGIS a plus de fonctionnalités et généralement de meilleures performances. De plus, les autres mentionnés (à l’exception de GeoMesa) ne sont pas open source.
Si vous êtes nouveau dans ce domaine, vous pourriez maintenant être confus: c’est donc un endroit pour stocker des données et vous devez obtenir des informations de manière complexe en écrivant des choses étranges sur la ligne de commande? Attends ça. Il y a aussi de réels avantages que PostGIS peut vous offrir si vous vous y engagez vraiment.
J’ai demandé quelques idées pour le billet de blog à Twitter et j’ai eu beaucoup de bons commentaires. De là, j’ai eu l’idée de diviser cela en deux parties. Dans la première partie, je vais examiner les avantages que PostGIS peut apporter à votre travail quotidien. Dans la deuxième partie, je me concentrerai davantage sur le SQL spatial.
PostGIS peut vous permettre d’adopter une nouvelle façon de travailler. Cette nouvelle méthode peut être plus facilement reproductible, vous pouvez commencer à utiliser le contrôle de version plus facilement et il peut activer des flux de travail multi-utilisateurs.Les fichiers
nécessitent souvent un logiciel spécial pour lire et écrire. SQL est une abstraction pour l’accès et l’analyse aléatoires des données. Sans cette abstraction, vous aurez besoin d’un logiciel spécifique pour effectuer les opérations ou d’écrire vous-même tout le code d’accès et d’analyse.
Faire votre analyse en SQL plutôt que de simplement faire des opérations aléatoires pour des fichiers avec des outils aléatoires avec des paramètres aléatoires, vous permet de partager et de reproduire vos résultats plus facilement. Vous pourriez avoir ce « fichier de formes principal » actuellement quelque part, où vous avez effectué plusieurs jointures spatiales et opérations de clip dans un fichier de formes pour que cela soit comme il est censé l’être. Et si ça disparaissait ?
Johnnie a écrit un bon exemple sur Twitter sur la façon dont il a accidentellement supprimé toutes ses données, mais a pu les reproduire avec un minimum d’effort avec les scripts SQL qu’il a enregistrés dans GIT.
Les personnes travaillant avec le développement de logiciels sont probablement (ou, espérons-le) familières avec le contrôle de version. Je ne vais pas approfondir cela dans cet article de blog, mais vous pouvez (et vous devriez) avoir vos scripts SQL dans un système de contrôle de version, comme GIT. Pensez-y comme un livre de recettes que vous gardez dans votre étagère et que vous mettez constamment à jour pour toujours trouver les meilleures recettes pour une analyse de données savoureuse. Seulement que vous pouvez acheter à nouveau une nouvelle copie de ce livre de recettes exact sur Amazon si votre maison brûle.
Une base de données peut également vous aider à conserver vos données spatiales dans un meilleur ordre. Aucun d’entre nous n’est vraiment parfait et vous allez probablement toujours créer des tables comme temp_1, final_final, mais une base de données vous offre une meilleure opportunité de standardiser votre structure de données que de simples fichiers (par exemple en standardisant les types de données dans vos tables).
Et qu’en est-il de ces grands ensembles de données? Avec une base de données spatiale, travailler avec de grands ensembles de données devient possible. Non seulement plus facile, mais il est parfois presque impossible de travailler sur des ensembles de données plus volumineux sans base de données. Avez-vous déjà essayé d’ouvrir un fichier csv de 2 Go? Ou essayé de faire du géotraitement pour un GeoJSON de 800 mo? Saviez-vous même que les fichiers de formes ont une limite de taille? Bien sûr, vous pouvez résoudre certains de ces problèmes en utilisant Geopackage ou d’autres formats de fichiers, mais en général, PostGIS est l’outil optimal pour gérer de grosses données (géospatiales).

Une fonctionnalité très intéressante avec les bases de données est que vous pouvez automatiser plus facilement les processus que vous faites normalement manuellement. Par exemple, en utilisant la fonctionnalité de NOTIFICATION PostgreSQL, vous pouvez mettre à jour vos cartes QGIS automatiquement. De plus, si vous travaillez avec des outils ETL (par exemple, FME) pour automatiser votre travail, la lecture/ écriture depuis /vers des tables PostGIS est beaucoup plus facile qu’avec des fichiers.
Si vous n’êtes pas comme moi (je fais actuellement ce genre de choses par moi-même et pour le plaisir), vous pourriez avoir une chose appelée une équipe. Également connu sous le nom de collègues. Ils pourraient avoir besoin d’accéder aux mêmes données que vous. L’utilisation d’une base de données dans votre flux de travail permet de travailler en parallèle complètement à un niveau différent du simple fait d’avoir des fichiers sur un lecteur partagé.
L’une des principales raisons en est que les utilisateurs simultanés peuvent provoquer une corruption. Bien qu’il soit possible d’écrire du code supplémentaire pour s’assurer que plusieurs écritures dans le même fichier ne corrompent pas les données, au moment où vous avez résolu le problème et également résolu le problème de performance associé, vous auriez écrit la meilleure partie d’un système de base de données.
Bien sûr, il y a des avantages et des inconvénients à adopter un nouveau flux de travail. Tout comme garder vos fichiers en ordre, à la fin de la journée, la maintenance d’une base de données peut également représenter beaucoup de travail. Par exemple, la mise à jour de votre PostGIS vers une nouvelle version peut être une vraie douleur, comme cela a été souligné sur Twitter. Avec un grand pouvoir vient une grande responsabilité.
Mais parlons plus de cette partie de puissance.
Partie 2: Le monde magique du SQL spatial
Le SQL spatial peut vraiment accélérer votre traitement (lorsqu’il est utilisé à bon escient). Vous trouverez ci-dessous une comparaison entre l’exécution du même processus avec un fichier de formes et le traitement QGIS, puis dans PostGIS avec ST_GeneratePoints.

Pour cette comparaison, j’avais des données de code postal de Finlande et de la population de chaque zone de code postal. J’avais cela à la fois comme fichier de formes et comme table dans ma base de données locale. J’ai créé des points aléatoires à l’intérieur de chaque polygone pour représenter la population. J’ai utilisé le traitement QGIS (Points aléatoires à l’intérieur du polygone à partir du traitement Vectoriel) pour le fichier de formes et dans PostGIS, le SQL était vraiment aussi simple que ceci:
SELECT ST_GeneratePoints(geom, he_vakiy) from paavo.paavo
Comme vous pouvez le voir sur le graphique ci-dessus, il a fallu moins de 10% du temps à PostGIS pour effectuer la même analyse par rapport à QGIS et à un fichier de formes. Si vous êtes un analyste SIG et que vous effectuez des processus comme celui-ci tous les jours, cela peut vous faire gagner beaucoup de temps en un an.
Outre un traitement plus rapide, vous pouvez profiter de la vaste sélection de fonctions spatiales que PostGIS a à offrir. Les fonctions qui vous sont les plus utiles dépendent totalement du cas d’utilisation. En plus de l’analyse Voronoï et de l’analyse SIG plus traditionnelle (tampon, superposition, intersection, clip, etc..) vous pouvez faire des choses plus avancées:
- Routage. Avec les données de pgRouting et de route, vous pouvez trouver des itinéraires optimaux et effectuer différentes analyses de réseau;
- Squelette de polygone. Cette fonction vous permet de construire l’axe médian d’un polygone à la volée ; Subdivision géométrique
- . Diviser vos géométries pour un traitement ultérieur peut accélérer considérablement vos processus ;
- Clustering. Trouvez des clusters et des modèles à partir de vos données. Avec le battage médiatique de l’IA au sommet, les k-means pourraient être encore plus intéressants pour certains qu’auparavant…
Pourquoi avez-vous besoin de choses comme la squelettisation de polygones? Peut-être une question valable pour la plupart, mais une fois que votre analyse spatiale en aura besoin, vous serez extrêmement ravi que quelqu’un ait fait le travail acharné (= mathématiques) pour vous. En combinant différentes fonctions spatiales et en utilisant les fonctions intégrées de Postgres avec elles, vous pourrez effectuer une analyse spatiale avancée dans votre base de données.
Les questions compliquées et intéressantes (jointures spatiales, agrégations, etc.) qui sont exprimables dans une ligne de SQL dans la base de données nécessitent beaucoup de puissance de calcul et c’est quelque chose que PostGIS vous offre. Répondre aux mêmes questions avec votre propre code peut prendre des centaines de lignes de code spécialisé pour répondre lors de la programmation par rapport à des fichiers.
PostGIS for dataviz
Dans de nombreuses visualisations que j’ai dans mon portfolio, PostGIS a joué un rôle dans le processus de visualisation. Dans mon flux de travail, le plus souvent, je pré-traite les données, puis je fais la visualisation réelle dans QGIS.
Voyons un exemple de l’un de ces processus.
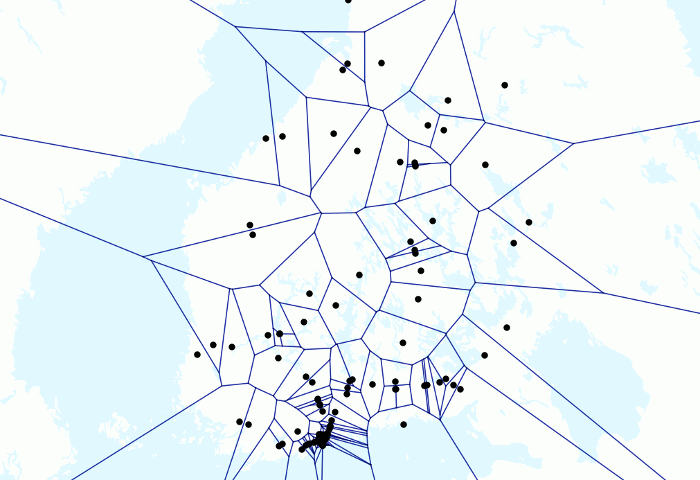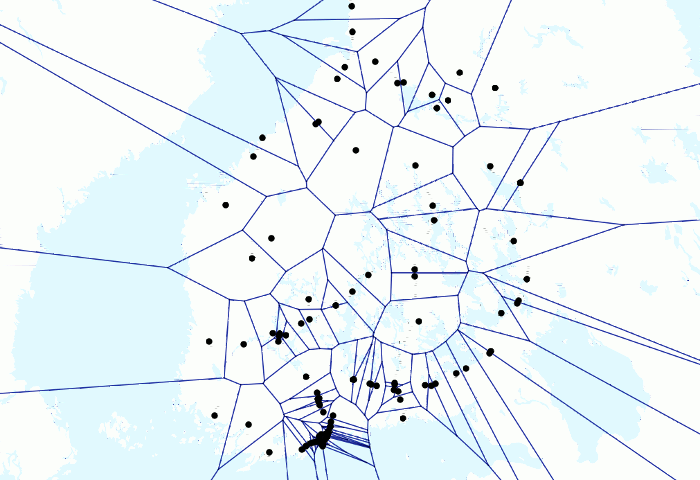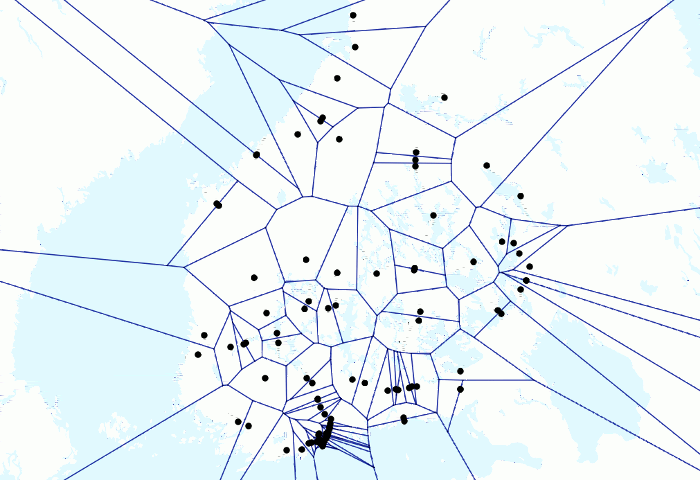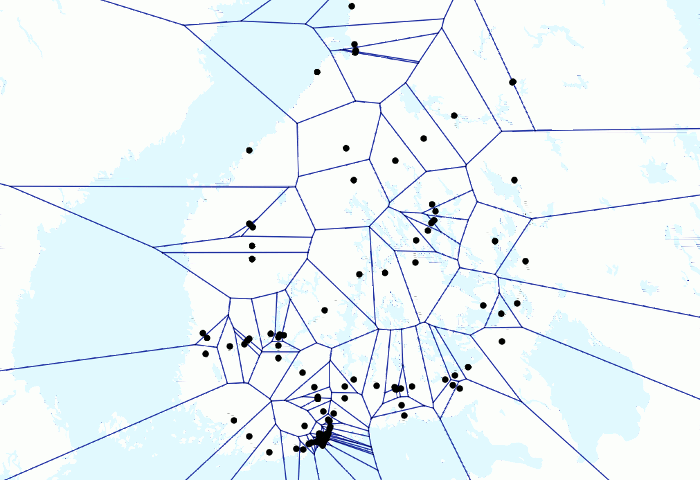
L’animation sur les trains et les voronois ci-dessus donne un exemple ludique de la puissance de PostGIS. J’avais quelques millions de points GPS de train dans ma base de données locale et j’avais déjà créé des animations avec les points en mouvement. Mais je voulais tester à quoi ressemblerait une animation avec des lignes de Voronoï.
D’abord parce que j’avais plusieurs points GPS pour chaque train par minute, je voulais les regrouper pour avoir un point représentatif pour chaque minute par train. J’avais d’abord créé une table manuellement pour les points résultants. J’ai écrit la requête suivante
INSERT INTO trains.voronoipoints
SELECT '2018–01–15 09:00:00' AS t,
geom
FROM (SELECT St_centroid(St_collect(geom)) AS geom,
trainno
FROM (SELECT geom,
trainno
FROM trains.week
WHERE time > '2018–01–15 09:00:00'
AND time < '2018–01–15 09:01:00') AS a
GROUP BY trainno) AS b
Si nous freinons la requête en morceaux, nous pouvons voir les pièces suivantes du puzzle:
- Vous pouvez voir certains des éléments normaux d’une requête SQL (INSERT INTO, SELECT, AS, FROM, WHERE ET GROUP BY)
- geom, trainno et time sont des noms de colonnes dans ma table de semaine dans le schéma appelé trains
- La sous-requête a renvoie tous les points GPS qui ont été suivis dans le délai demandé.
- Parce que je sélectionne tous les points GPS suivis en une minute, je pourrais obtenir plusieurs points pour chaque train. Je n’en voulais qu’un, pour que les lignes de voronoi semblent plus sensées. C’est pourquoi j’utilise ST_Collect pour regrouper les points et en créer une géométrie multipoint. ST_Centroid remplace la géométrie multipoint par un point unique situé au centroïde (sous-requête b) et les données sont regroupées par numéros de train.
Pour faire la même chose plusieurs fois, j’avais un script Python simple pour boucler la même requête plusieurs centaines de fois où j’avais les heures de début et de fin comme paramètres. Après avoir réussi à trouver un point représentatif pour chaque minute, je viens d’exécuter la commande suivante (en 11,5 secondes):
SELECT t, ST_VoronoiLines(geom) from trains.voronoipoints
Puis j’ai ajouté le résultat à QGIS et l’ai visualisé avec Time Manager. Cela peut être un moyen un peu hacky d’obtenir le résultat et un utilisateur SQL plus expérimenté l’a peut-être fait complètement avec une seule commande SQL, mais je suis toujours assez satisfait du résultat. Bien que cela puisse être inutile.
Finalement assez simple, mais le résultat ressemble à des mathématiques de niveau supérieur (et c’est le cas!), car tout le travail est fait par PostGIS. De plus, comme j’ai pu faire l’analyse de Voronoï pour un seul point par train, le temps de traitement n’était que de quelques secondes pour des centaines de milliers de points.
Souvent, le temps de traitement de vos requêtes augmente de manière exponentielle à mesure que les quantités de données augmentent. C’est pourquoi vous devez être intelligent avec vos requêtes.

En règle générale, plus une requête doit récupérer de données et plus la base de données doit effectuer d’opérations (commande, regroupement, etc.), elle devient plus lente et donc moins efficace. Une requête SQL efficace ne récupère que les lignes et les colonnes dont elle a vraiment besoin. SQL peut fonctionner comme un casse-tête logique, où vous devez vraiment réfléchir à fond à ce que vous voulez réaliser.
Je dois également noter que peaufiner les performances de vos requêtes est une pente glissante et vous pouvez vous perdre dans le monde de l’optimisation sans fin. Trouver l’équilibre entre une « requête optimale » et une requête optimale est vraiment important. Surtout si vous ne construisez pas d’application pour un million d’utilisateurs, quelques millisecondes ici ou là ne feront probablement pas basculer votre bateau.
Comment commencer?
J’ose dire que l’apprentissage de SQL est encore plus bénéfique pour un utilisateur SIG moyen que l’apprentissage de JavaScript, Python ou R. La syntaxe SQL n’a subi que des changements mineurs au fil des ans et les compétences SQL sont très bien transférables.
J’ai trouvé que la courbe d’apprentissage en SQL n’est pas vraiment raide pour faire les bases, mais cela pourrait vous prendre un certain temps pour voir vraiment les avantages qu’elle peut apporter à votre analyse spatiale. Mais j’encourage à être patient et à essayer des analyses plus compliquées et à viser un traitement plus rapide. Finalement, vous verrez la différence.
Tout d’abord, lorsque vous apprenez les bases de SQL, vous apprendrez à interroger des données à partir d’une seule table à l’aide de techniques de sélection de données de base telles que la sélection de colonnes, le tri du jeu de résultats et le filtrage des lignes. Ensuite, vous en apprendrez plus sur les requêtes avancées telles que la jonction de plusieurs tables, l’utilisation d’opérations de définition et la construction d’une sous-requête. Enfin, vous apprendrez à gérer les tables de base de données, telles que la création d’une nouvelle table ou la modification de la structure d’une table existante.
Mais il y a aussi des outils pour vous aider!
QGIS dispose d’un excellent outil appelé DB Manager. Il offre une interface graphique similaire pour votre base de données, mais de manière beaucoup plus compressée et à l’intérieur de QGIS. Vous pouvez modifier et ajouter des tables, ajouter des index et effectuer de nombreuses opérations de base de manière cliquable à droite.

Vous devriez également vérifier pgAdmin, qui est la plate-forme d’administration et de développement la plus populaire pour PostgreSQL. Il existe plusieurs façons de transférer vos données vers PostGIS (par exemple, ogr2ogr, shp2pgsql). En général, j’encourage à essayer différents outils et méthodes de travail avec les données.
J’ai fait quelques petites expériences en combinant Python et PostGIS. Travailler ensemble avec Python (ou R) et PostGIS peut vraiment faire passer le traitement et l’automatisation de vos données au niveau supérieur. Il suffit de combiner les capacités de script de base de Python et de se connecter à PostGIS à l’aide de psycopg2 pour commencer.
Avez-vous envie de commencer avec PostGIS ?
- Il suffit de télécharger les programmes d’installation et d’installer PostGIS sur votre machine locale. Suivez les instructions des tutoriels;
- Chargez-y des données. Commencez avec un seul fichier de formes en utilisant QGIS DB Manager ou chech, par exemple, ce tutoriel sur la façon d’obtenir des données de Terre naturelle dans PostGIS;
- Commencez à jouer avec SQL. Commencez par les bases (sélection, filtrage et modification des données) et lentement, vous verrez quels types d’avantages cela pourrait apporter à votre flux de travail.
Conclusions
Si votre façon de travailler est actuellement inefficace, le simple fait de changer vos outils ne rendra pas votre résultat meilleur ou le processus moins douloureux. Vous devez changer votre façon de penser la gestion des données. Il existe de nombreuses façons d’utiliser les bases de données de manière inefficace. Croyez-moi, je les ai vus et même essayé quelques-uns.
Changer aussi les choses juste pour le changement, n’a pas de sens. Si votre travail quotidien ne fait que tracer quelques points sur une carte de temps en temps, vous pouvez très bien le faire avec des fichiers de formes et des fichiers csv également à l’avenir. Peut-être même plus efficace de cette façon.
MAIS.
Si vous voulez faire des analyses spatiales sérieuses, automatiser vos processus ou de quelque manière que ce soit faire passer votre façon de travailler avec les données spatiales au niveau supérieur, je peux fortement vous recommander de vous familiariser avec PostGIS et en particulier spatial SQL. Apprendre SQL peut également être amusant. Sérieusement.
Dernier point mais certainement pas le moindre. Comme Tom l’a souligné: l’utilisation de PostGIS vous donne du crédit à geohipster!

Une chose que je n’ai mentionnée que brièvement était que PostGIS est open source et disponible gratuitement. Cela signifie que les personnes travaillant avec un petit budget ou sans budget (comme moi) n’ont aucune barrière d’entrée. Les bases de données spatiales commerciales peuvent être extrêmement coûteuses. Un grand merci à tous les développeurs actifs travaillant sur le projet!
Merci d’avoir lu! Consultez mon site Web pour plus d’informations sur moi ou envoyez-moi un commentaire sur Twitter.
Vous voulez en savoir plus ? Sources pour cet article de blog et d’autres articles de lecture de GIS
RTFD. La documentation PostGIS est vraiment bonne.
Le gourou de PostGIS Paul Ramsey a plusieurs présentations sur le sujet de différents points de vue sur son site
De superbes documents de Boundless sur l’introduction à PostGIS.
Anita Graser a écrit une formidable série de billets de blog sur la gestion des données de mouvement dans PostGIS.
Consultez les livres PostGIS de Regina Obe
J’ai utilisé ce tutoriel SIG de Boston lorsque j’ai installé PostGIS localement pour la première fois
Extra pour les personnes qui font du dataviz: une expérience intéressante sur le stockage des couleurs sous forme de points 3D dans PostGIS