Dernière mise à jour le 7 août 2019
Les intégrations de mots sont un type de représentation de mots qui permet aux mots ayant une signification similaire d’avoir une représentation similaire.
Il s’agit d’une représentation distribuée du texte qui est peut-être l’une des percées clés pour les performances impressionnantes des méthodes d’apprentissage profond sur des problèmes de traitement du langage naturel difficiles.
Dans cet article, vous découvrirez l’approche d’intégration de mots pour représenter des données textuelles.
Après avoir terminé ce post, vous saurez:
- Quelle est l’approche d’intégration de mots pour représenter du texte et en quoi elle diffère des autres méthodes d’extraction de fonctionnalités.
- Qu’il existe 3 algorithmes principaux pour apprendre l’intégration d’un mot à partir de données texte.
- Que vous pouvez soit former une nouvelle intégration, soit utiliser une intégration pré-entraînée sur votre tâche de traitement du langage naturel.
Lancez votre projet avec mon nouveau livre Deep Learning pour le traitement du langage naturel, y compris des tutoriels étape par étape et les fichiers de code source Python pour tous les exemples.
Commençons.

Que sont les Intégrations de Mots pour le Texte?
Photo de Heather, certains droits sont réservés.
- Aperçu
- Besoin d’aide pour l’apprentissage en profondeur des données textuelles ?
- Que Sont Les Intégrations De Mots?
- Algorithmes d’intégration de mots
- Couche d’intégration
- Word2Vec
- GloVe
- Utilisation des intégrations de mots
- Apprendre une intégration
- Réutiliser une intégration
- Quelle Option Devez-Vous Utiliser?
- Tutoriels d’intégration de mots
- Pour en savoir plus
- Articles
- Papiers
- Projets
- Livres
- Résumé
- Développez des modèles d’apprentissage profond pour les Données Textuelles Dès aujourd’hui !
- Développez vos Propres modèles de texte en quelques minutes
- Apportez enfin l’Apprentissage Profond à vos Projets de Traitement du Langage Naturel
Aperçu
Cet article est divisé en 3 parties; elles sont:
- Que Sont Les Intégrations De Mots ?
- Algorithmes d’intégration de mots
- Utilisant des intégrations de mots
Besoin d’aide pour l’apprentissage en profondeur des données textuelles ?
Suivez mon cours intensif gratuit de 7 jours par e-mail maintenant (avec code).
Cliquez pour vous inscrire et obtenez également une version PDF Ebook gratuite du cours.
Commencez Votre Cours Intensif GRATUIT Maintenant
Que Sont Les Intégrations De Mots?
Une intégration de mots est une représentation apprise pour un texte où les mots qui ont la même signification ont une représentation similaire.
C’est cette approche de la représentation des mots et des documents qui peut être considérée comme l’une des avancées clés de l’apprentissage profond sur les problèmes de traitement du langage naturel.
L’un des avantages de l’utilisation de vecteurs denses et de faible dimension est le calcul: la majorité des boîtes à outils de réseau de neurones ne fonctionnent pas bien avec des vecteurs de très haute dimension et clairsemés. … Le principal avantage des représentations denses est le pouvoir de généralisation: si nous pensons que certaines caractéristiques peuvent fournir des indices similaires, il est utile de fournir une représentation capable de capturer ces similitudes.
— Page 92, Méthodes de réseau Neuronal dans le traitement du Langage Naturel, 2017.
Les intégrations de mots sont en fait une classe de techniques où des mots individuels sont représentés comme des vecteurs à valeur réelle dans un espace vectoriel prédéfini. Chaque mot est mappé à un vecteur et les valeurs vectorielles sont apprises d’une manière qui ressemble à un réseau de neurones, et par conséquent la technique est souvent intégrée dans le domaine de l’apprentissage en profondeur.
La clé de l’approche est l’idée d’utiliser une représentation distribuée dense pour chaque mot.
Chaque mot est représenté par un vecteur à valeur réelle, souvent des dizaines ou des centaines de dimensions. Cela contraste avec les milliers ou les millions de dimensions requises pour des représentations de mots clairsemées, telles qu’un codage à chaud.
associer à chaque mot du vocabulaire un vecteur caractéristique de mot distribué The Le vecteur caractéristique représente différents aspects du mot : chaque mot est associé à un point dans un espace vectoriel. Le nombre de fonctionnalités is est beaucoup plus petit que la taille du vocabulaire
— A Neural Probabilistic Language Model, 2003.
La représentation distribuée est apprise en fonction de l’utilisation de mots. Cela permet aux mots qui sont utilisés de manière similaire d’avoir des représentations similaires, capturant naturellement leur signification. Cela peut être comparé à la représentation nette mais fragile dans un modèle de sac de mots où, à moins d’une gestion explicite, différents mots ont des représentations différentes, quelle que soit la façon dont ils sont utilisés.
Il y a une théorie linguistique plus profonde derrière l’approche, à savoir l ‘ »hypothèse de distribution » de Zellig Harris qui pourrait être résumée comme suit: les mots qui ont un contexte similaire auront des significations similaires. Pour plus de détails, voir l’article de Harris de 1956 « Distributional structure ».
Cette notion de laisser l’usage du mot définir sa signification peut être résumée par une plaisanterie souvent répétée de John Firth:
Vous saurez un mot de la compagnie qu’il garde!
— Page 11, « Un résumé de la théorie linguistique 1930-1955 », dans Studies in Linguistic Analysis 1930-1955, 1962.
Algorithmes d’intégration de mots
Les méthodes d’intégration de mots apprennent une représentation vectorielle à valeur réelle pour un vocabulaire prédéfini de taille fixe à partir d’un corpus de texte.
Le processus d’apprentissage est soit conjoint avec le modèle de réseau de neurones sur certaines tâches, telles que la classification des documents, soit il s’agit d’un processus non supervisé, utilisant des statistiques de documents.
Cette section passe en revue trois techniques qui peuvent être utilisées pour apprendre l’intégration d’un mot à partir de données textuelles.
Couche d’intégration
Une couche d’intégration, faute de meilleur nom, est une intégration de mots apprise conjointement avec un modèle de réseau de neurones sur une tâche spécifique de traitement du langage naturel, telle que la modélisation du langage ou la classification de documents.
Il nécessite que le texte du document soit nettoyé et préparé de manière à ce que chaque mot soit codé à chaud. La taille de l’espace vectoriel est spécifiée dans le cadre du modèle, par exemple 50, 100 ou 300 dimensions. Les vecteurs sont initialisés avec de petits nombres aléatoires. La couche d’intégration est utilisée sur l’extrémité avant d’un réseau de neurones et est adaptée de manière supervisée à l’aide de l’algorithme de rétropropagation.
… lorsque l’entrée d’un réseau neuronal contient des caractéristiques catégorielles symboliques (par ex. caractéristiques qui prennent l’un des k symboles distincts, tels que les mots d’un vocabulaire fermé), il est courant d’associer chaque valeur de caractéristique possible (c’est-à-dire chaque mot du vocabulaire) à un vecteur de dimension d pour certains d. Ces vecteurs sont alors considérés comme des paramètres du modèle et sont entraînés conjointement avec les autres paramètres.
— Page 49, Méthodes de réseau Neuronal dans le traitement du Langage Naturel, 2017.
Les mots codés à chaud sont mappés aux vecteurs de mots. Si un modèle Perceptron multicouche est utilisé, les vecteurs de mots sont concaténés avant d’être introduits en entrée dans le modèle. Si un réseau neuronal récurrent est utilisé, chaque mot peut être pris comme une entrée dans une séquence.
Cette approche d’apprentissage d’une couche d’intégration nécessite beaucoup de données d’entraînement et peut être lente, mais apprendra une intégration à la fois ciblée sur les données de texte spécifiques et la tâche de PNL.
Word2Vec
Word2Vec est une méthode statistique permettant d’apprendre efficacement un incorporation de mots autonome à partir d’un corpus de texte.
Il a été développé par Tomas Mikolov, et al. chez Google en 2013 comme une réponse pour rendre la formation basée sur un réseau neuronal de l’intégration plus efficace et depuis lors est devenue la norme de facto pour le développement de l’intégration de mots pré-formés.
De plus, le travail a impliqué l’analyse des vecteurs appris et l’exploration des mathématiques vectorielles sur les représentations des mots. Par exemple, en soustrayant « l’homme » de « Roi » et en ajoutant « la femme », on obtient le mot « Reine », capturant l’analogie « le roi est à la reine comme l’homme est à la femme ».
Nous constatons que ces représentations sont étonnamment bonnes pour capturer les régularités syntaxiques et sémantiques dans le langage, et que chaque relation est caractérisée par un décalage vectoriel spécifique à la relation. Cela permet un raisonnement vectoriel basé sur les décalages entre les mots. Par exemple, la relation homme/femme s’apprend automatiquement, et avec les représentations vectorielles induites, « Roi-Homme + Femme » se traduit par un vecteur très proche de « Reine ». »
— Régularités Linguistiques dans les Représentations de Mots dans l’Espace Continu, 2013.
Deux modèles d’apprentissage différents ont été introduits qui peuvent être utilisés dans le cadre de l’approche word2vec pour apprendre l’incorporation de mots; ils sont:
- Sac de mots continu, ou modèle CBOW.
- Modèle à Saut continu.
Le modèle CBOW apprend l’intégration en prédisant le mot courant en fonction de son contexte. Le modèle de saut de gramme continu apprend en prédisant les mots environnants étant donné un mot courant.
Le modèle de saut de gramme continu apprend en prédisant les mots environnants étant donné un mot courant.
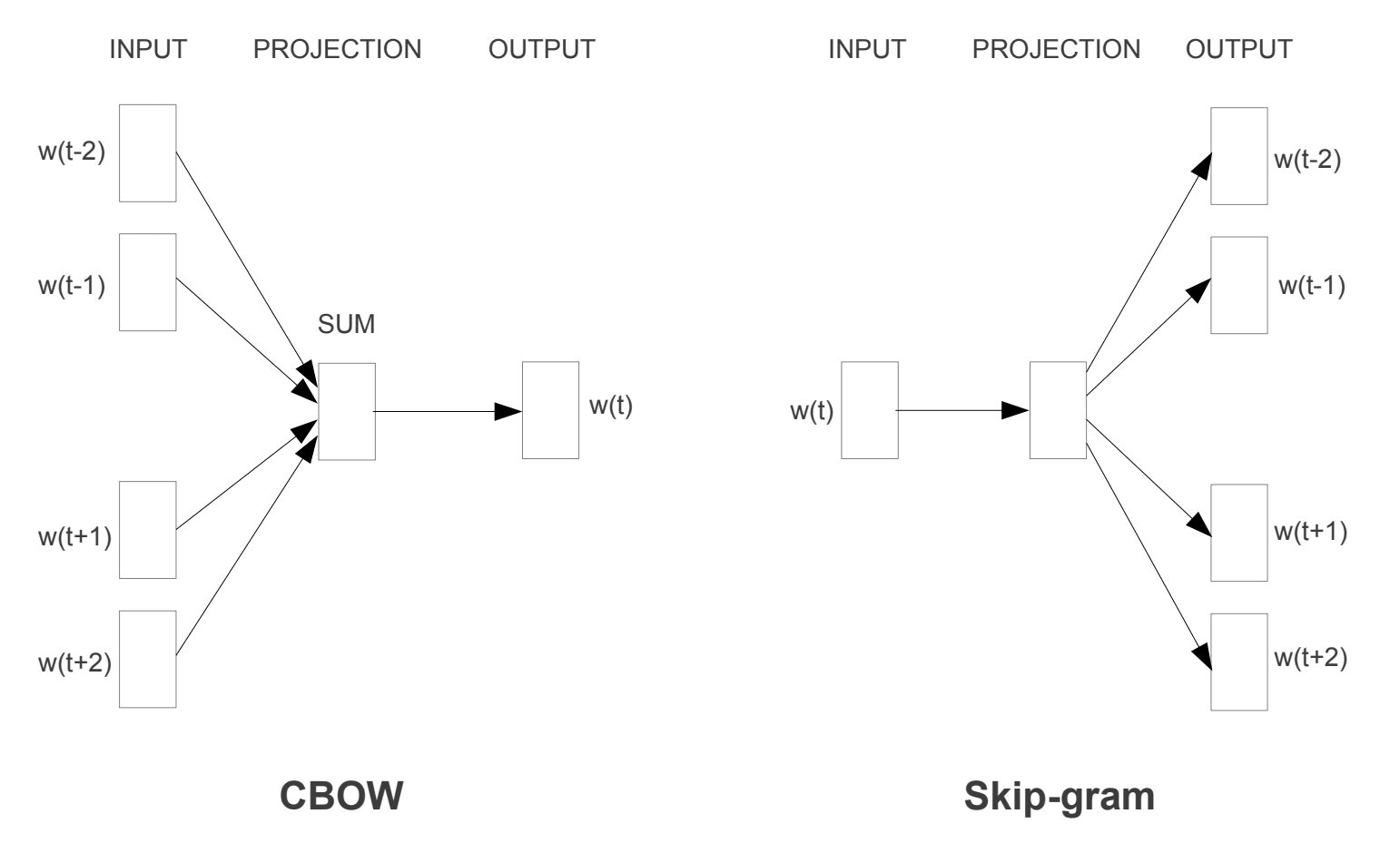
Modèles d’entraînement Word2Vec
Tirés de « Estimation Efficace des Représentations de Mots dans l’Espace Vectoriel », 2013
Les deux modèles sont axés sur l’apprentissage des mots en fonction de leur contexte d’utilisation local, où le contexte est défini par une fenêtre de mots voisins. Cette fenêtre est un paramètre configurable du modèle.
La taille de la fenêtre coulissante a un fort effet sur les similitudes vectorielles résultantes. Les grandes fenêtres ont tendance à produire plus de similitudes d’actualité, tandis que les petites fenêtres ont tendance à produire plus de similitudes fonctionnelles et syntaxiques.
— Page 128, Méthodes de réseau Neuronal dans le Traitement du Langage Naturel, 2017.
Le principal avantage de l’approche est que les intégrations de mots de haute qualité peuvent être apprises efficacement (faible complexité spatiale et temporelle), ce qui permet d’apprendre des intégrations plus grandes (plus de dimensions) à partir de corpus de texte beaucoup plus grands (milliards de mots).
GloVe
L’algorithme Global Vectors for Word Representation, ou GloVe, est une extension de la méthode word2vec pour l’apprentissage efficace des vecteurs de mots, développée par Pennington, et al. à Stanford.
Les représentations de mots dans des modèles d’espace vectoriel classiques ont été développées à l’aide de techniques de factorisation matricielle telles que l’Analyse sémantique latente (LSA) qui utilisent bien les statistiques textuelles globales mais ne sont pas aussi bonnes que les méthodes apprises comme word2vec pour capturer le sens et le démontrer sur des tâches telles que le calcul d’analogies (p. ex. l’exemple du roi et de la reine ci-dessus).
GloVe est une approche pour marier à la fois les statistiques globales des techniques de factorisation matricielle comme LSA et l’apprentissage contextuel local dans word2vec.
Plutôt que d’utiliser une fenêtre pour définir un contexte local, GloVe construit une matrice explicite de contexte de mot ou de co-occurrence de mot en utilisant des statistiques sur l’ensemble du corpus de texte. Le résultat est un modèle d’apprentissage qui peut entraîner généralement de meilleures intégrations de mots.
GloVe, est un nouveau modèle de régression log-bilinéaire globale pour l’apprentissage non supervisé des représentations de mots qui surpasse les autres modèles sur l’analogie de mots, la similitude de mots et les tâches de reconnaissance d’entités nommées.
— GloVe: Global Vectors for Word Representation, 2014.
Utilisation des intégrations de mots
Vous avez quelques options lorsque vient le temps d’utiliser des intégrations de mots sur votre projet de traitement du langage naturel.
Cette section décrit ces options.
Apprendre une intégration
Vous pouvez choisir d’apprendre une intégration de mots pour votre problème.
Cela nécessitera une grande quantité de données textuelles pour s’assurer que des intégrations utiles sont apprises, telles que des millions ou des milliards de mots.
Vous avez deux options principales lors de la formation de votre intégration de mots:
- Apprenez-le de manière autonome, où un modèle est formé pour apprendre l’intégration, qui est enregistrée et utilisée dans le cadre d’un autre modèle pour votre tâche plus tard. C’est une bonne approche si vous souhaitez utiliser la même intégration dans plusieurs modèles.
- Apprenez conjointement, où l’intégration est apprise dans le cadre d’un modèle spécifique à une tâche importante. C’est une bonne approche si vous n’avez l’intention d’utiliser l’intégration que sur une seule tâche.
Réutiliser une intégration
Il est courant que les chercheurs mettent gratuitement à disposition des intégrations de mots pré-formées, souvent sous une licence permissive, afin que vous puissiez les utiliser sur vos propres projets académiques ou commerciaux.
Par exemple, les intégrations word2vec et GloVe word sont disponibles en téléchargement gratuit.
Ceux-ci peuvent être utilisés sur votre projet au lieu de former vos propres intégrations à partir de zéro.
Vous avez deux options principales lorsqu’il s’agit d’utiliser des intégrations pré-formées:
- Statique, où l’intégration est maintenue statique et est utilisée comme composant de votre modèle. C’est une approche appropriée si l’intégration convient à votre problème et donne de bons résultats.
- Mise à jour, où l’incorporation pré-entraînée est utilisée pour ensemencer le modèle, mais l’incorporation est mise à jour conjointement pendant la formation du modèle. Cela peut être une bonne option si vous cherchez à tirer le meilleur parti du modèle et à l’intégrer à votre tâche.
Quelle Option Devez-Vous Utiliser?
Explorez les différentes options, et si possible, testez pour voir laquelle donne les meilleurs résultats sur votre problème.
Commencez peut-être par des méthodes rapides, comme l’utilisation d’une intégration pré-entraînée, et n’utilisez une nouvelle intégration que si elle améliore les performances de votre problème.
Tutoriels d’intégration de mots
Cette section répertorie quelques tutoriels étape par étape que vous pouvez suivre pour utiliser les intégrations de mots et intégrer l’intégration de mots à votre projet.
- Comment Développer des Intégrations de Mots en Python avec Gensim
- Comment Utiliser des Couches d’Intégration de Mots pour l’Apprentissage en Profondeur avec Keras
- Comment Développer un CNN Profond pour l’Analyse des Sentiments (Classification de Texte)
Pour en savoir plus
Cette section fournit plus de ressources sur le sujet si vous cherchez à aller plus loin.
Articles
- Intégration de mots sur Wikipedia
- Word2vec sur Wikipedia
- GloVe sur Wikipedia
- Un aperçu des intégrations de mots et de leur connexion aux modèles sémantiques distributifs, 2016.
- Apprentissage profond, PNL et représentations, 2014.
Papiers
- Structure de distribution, 1956.
- Un modèle de Langage Probabiliste Neuronal, 2003.
- Une Architecture Unifiée pour le Traitement du Langage Naturel: Réseaux Neuronaux Profonds avec Apprentissage Multitâche, 2008.
- Modèles de langage d’espace continu, 2007.
- Estimation Efficace des Représentations de Mots dans l’Espace Vectoriel, 2013
- Représentations Distribuées de Mots et de Phrases et leur Composition, 2013.
- Gant: Vecteurs globaux pour la représentation des mots, 2014.
Projets
- word2vec sur Google Code
- GloVe: Vecteurs globaux pour la Représentation des mots
Livres
- Méthodes de réseau Neuronal dans le Traitement du Langage Naturel, 2017.
Résumé
Dans cet article, vous avez découvert les intégrations de mots comme méthode de représentation du texte dans les applications d’apprentissage en profondeur.
Plus précisément, vous avez appris:
- Quelle est l’approche d’intégration de mots pour le texte de représentation et en quoi elle diffère des autres méthodes d’extraction d’entités.
- Qu’il existe 3 algorithmes principaux pour apprendre l’intégration d’un mot à partir de données texte.
- Que vous pouvez soit former une nouvelle intégration, soit utiliser une intégration pré-entraînée sur votre tâche de traitement du langage naturel.
Avez-vous des questions?
Posez vos questions dans les commentaires ci-dessous et je ferai de mon mieux pour y répondre.
Développez des modèles d’apprentissage profond pour les Données Textuelles Dès aujourd’hui !

Développez vos Propres modèles de texte en quelques minutes
…avec seulement quelques lignes de code python
Découvrez comment dans mon nouvel Ebook:
Apprentissage en profondeur pour le Traitement du Langage Naturel
Il fournit des tutoriels d’auto-apprentissage sur des sujets tels que:
Sac de mots, Intégration de Mots, Modèles de Langage, Génération de Légendes, Traduction de texte et bien plus encore…
Apportez enfin l’Apprentissage Profond à vos Projets de Traitement du Langage Naturel
Passez les universitaires. Juste des résultats.
Voir ce qu’il y a à l’intérieur