som datavetenskapare inom konsumentindustrin, vad jag brukar känna är att boosting algoritmer är tillräckligt för de flesta av de prediktiva inlärningsuppgifterna, åtminstone nu. De är kraftfulla, flexibla och kan tolkas snyggt med några knep. Således tror jag att det är nödvändigt att läsa igenom några material och skriva något om de boostande algoritmerna.
det mesta av innehållet i denna acticle är baserat på papperet: Trädförstärkning med XGBoost: varför vinner XGBoost ”varje” Maskininlärningstävling?. Det är ett riktigt informativt papper. Nästan allt om att öka algoritmer förklaras mycket tydligt i papperet. Så papperet innehåller 110 sidor 🙁
för mig kommer jag i princip att fokusera på de tre mest populära boostningsalgoritmerna: AdaBoost, GBM och XGBoost. Jag har delat innehållet i två delar. Den första artikeln (den här) kommer att fokusera på AdaBoost-algoritmen, och den andra kommer att vända sig till jämförelsen mellan GBM och XGBoost.
AdaBoost, kort för ”Adaptive Boosting”, är den första praktiska boostningsalgoritmen som Freund och Schapire föreslog 1996. Det fokuserar på klassificeringsproblem och syftar till att omvandla en uppsättning svaga klassificerare till en stark. Den slutliga ekvationen för klassificering kan representeras som
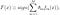
där f_m står för m_th svag klassificerare och theta_m är motsvarande vikt. Det är exakt den viktade kombinationen av m svaga klassificerare. Hela proceduren i AdaBoost-algoritmen kan sammanfattas enligt följande.
AdaBoost algoritm
ges en datamängd som innehåller n poäng, där

här -1 betecknar den negativa klassen medan 1 representerar den positiva.
initiera vikten för varje datapunkt som:

för iteration m=1,…, M:
(1) Montera svaga klassificerare till datamängden och välj den med det lägsta vägda klassificeringsfelet:

(2) beräkna vikten för m_th svag klassificerare:

för varje klassificerare med noggrannhet högre än 50% är vikten positiv. Ju mer exakt klassificeraren desto större är vikten. Medan för klassificeraren med mindre än 50% noggrannhet är vikten negativ. Det betyder att vi kombinerar dess förutsägelse genom att vända tecknet. Till exempel kan vi förvandla en klassificerare med 40% noggrannhet till 60% noggrannhet genom att vända tecknet på förutsägelsen. Således fungerar även klassificeraren sämre än slumpmässig gissning, Det bidrar fortfarande till den slutliga förutsägelsen. Vi vill bara inte ha någon klassificerare med exakt 50% noggrannhet, vilket inte lägger till någon information och därmed inte bidrar till den slutliga förutsägelsen.
(3) Uppdatera vikten för varje datapunkt som:

där Z_m är en normaliseringsfaktor som säkerställer att summan av alla instansvikter är lika med 1.
om ett felklassificerat fall kommer från en positiv viktad klassificerare, skulle ”exp” – termen i täljaren alltid vara större än 1 (y*f är alltid -1, theta_m är positiv). Således skulle felklassificerade fall uppdateras med större vikter efter en iteration. Samma logik gäller för de negativa vägda klassificerarna. Den enda skillnaden är att de ursprungliga korrekta klassificeringarna skulle bli felklassificeringar efter att ha vänt tecknet.
efter M-iteration kan vi få den slutliga förutsägelsen genom att summera den viktade förutsägelsen för varje klassificerare.
AdaBoost som en framåtriktad Additivmodell
denna del är baserad på papper: additiv logistisk regression: en statistisk vy av boosting. För mer detaljerad information, se originalpapperet.
år 2000 Friedman et al. utvecklat en statistisk bild av AdaBoost-algoritmen. De tolkade AdaBoost som stagewise uppskattningsförfaranden för montering av en additiv logistisk regressionsmodell. De visade att AdaBoost faktiskt minimerade den exponentiella förlustfunktionen

det minimeras vid

eftersom för AdaBoost kan y bara vara -1 eller 1, kan förlustfunktionen skrivas om som

fortsätt att lösa för F (x), vi får

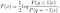
vi kan vidare härleda den normala logistiska modellen från den optimala lösningen av F (x):

det är nästan identiskt med den logistiska regressionsmodellen trots en faktor 2.
Antag att vi har en aktuell uppskattning av F (x) och försök att söka en förbättrad uppskattning F(x)+cf(x). För fast c och x kan vi expandera L(y, F(x)+cf(x)) till andra ordningen om f (x)=0,

således,

där E_w (./ x) indikerar en viktad villkorlig förväntan och vikten för varje datapunkt beräknas som

om c > 0 är minimering av den viktade villkorliga förväntan lika med maximering

eftersom y bara kan vara 1 eller -1 kan den vägda förväntan skrivas om som

den optimala lösningen kommer som

efter bestämning av f(x) kan vikten c beräknas genom att direkt minimera L (y, F (x) + cf (x)):

lösning för c, vi får


låt epsilon vara lika med den vägda summan av felklassificerade fall, då

Observera att c kan vara negativt om den svaga eleven gör sämre än slumpmässig gissning (50%), i vilket fall det automatiskt vänder polariteten.
när det gäller instansvikter, efter det förbättrade tillägget, blir vikten för en enda instans,

således uppdateras instansvikten som

jämfört med de som används i AdaBoost-algoritmen,

vi kan se att de är i identisk form. Därför är det rimligt att tolka AdaBoost som en framåtriktad additivmodell med exponentiell förlustfunktion, som iterativt passar en svag klassificerare för att förbättra den aktuella uppskattningen vid varje iteration m:
