det finns också ett antal felaktiga sätt att inkludera variabler. En gravitationsmodell fungerar inte om inte varje variabel uppfyller följande kriterier:
- numerisk
- komplett
- pålitlig
endast numeriska Data
eftersom gravitationsmodellen är en matematisk ekvation måste alla ingångsvariabler vara numeriska. Det kan vara en räkning (befolkning), rumslig åtgärd (område, avstånd, etc), tid (timmar från London till fots), procentandel (löneökning/minskning), valutavärde (löner i shilling) eller något annat mått på de platser som är involverade i modellen.
siffror måste vara meningsfulla och kan inte vara nominella kategoriska variabler som fungerar som en stand-in för ett kvalitativt attribut. Till exempel kan du inte godtyckligt tilldela ett nummer och använda det i modellen om numret inte har betydelse (t.ex. road quality = bra eller road quality = 4). Även om det senare är numeriskt är det inte ett mått på vägkvalitet. Istället kan du använda den genomsnittliga körhastigheten i miles per timme som en proxy för vägkvalitet. Huruvida medelhastighet är ett meningsfullt mått på vägkvalitet är upp till dig att bestämma och försvara som författare till studien.
generellt sett, om du kan mäta det eller räkna det, kan du modellera det.
endast fullständiga Data
alla kategorier av data måste finnas för varje intressepunkt. Det innebär att alla de 32 länen som analyseras måste ha tillförlitliga uppgifter för varje push and pull-faktor. Du kan inte ha några luckor eller tomma ämnen, till exempel ett län där du inte har genomsnittslönen.
endast tillförlitliga Data
datavetenskapsordspråket ”garbage in, garbage out” gäller även gravitationsmodeller, som bara är lika tillförlitliga som de data som används för att bygga dem. Utöver att välja robusta och tillförlitliga historiska data från källor du kan lita på, finns det många sätt att göra misstag som gör utgångarna från din modell meningslösa. Det är till exempel värt att se till att de data du har exakt matchar territorierna (t.ex. länsdata för att representera län, inte stadsdata för att representera ett län).
beroende på tid och plats för din studie kan det vara svårt att få en tillförlitlig uppsättning data för att basera din modell. Ju längre tillbaka i det förflutna en studie, desto svårare kan det vara. På samma sätt kan det vara lättare att genomföra dessa typer av analyser i samhällen som var kraftigt byråkratiska och lämnade ett bra överlevande pappersspår, till exempel i Europa eller Nordamerika.
för att säkerställa datakvaliteten i denna fallstudie beräknades varje variabel antingen tillförlitligt eller härleddes från publicerade peer-reviewed historiska data (se Tabell 1). Exakt hur dessa data sammanställdes kan läsas i den ursprungliga artikeln där den förklarades på djupet.11
våra fem Modellvariabler
med ovanstående principer i åtanke kunde vi ha valt ett antal variabler, med tanke på vad vi visste om migration push and pull-faktorer. Vi bestämde oss för fem (5), valda utifrån vad vi trodde skulle vara viktigast, och som vi visste kunde säkerhetskopieras med tillförlitliga data.
| variabel | källa |
|---|---|
| befolkning vid ursprung | 1771 värden, Wrigley,” engelska länspopulationer”, s.54-5.12 |
| avstånd från London | beräknat med programvara |
| pris på vete | kanon och Brunt,” veckovisa Brittiska spannmålspriser”13 |
| genomsnittliga löner vid ursprung | Hunt, ”industrialisering och Regional ojämlikhet”, s. 965-6.14 |
| bana av löner | Hunt, ”industrialisering och Regional ojämlikhet”, s. 965-6.15 |
Tabell 1: De fem variablerna som användes i modellen och källan till var och en i den peer reviewed litteraturen
efter att ha beslutat om dessa variabler bestämde medförfattare till den ursprungliga studien, Adam Dennett, att skriva om formeln för att göra det självdokumenterande så att det var lätt att berätta vilka bitar som hänför sig till var och en av dessa fem variabler. Det är därför formeln som visas ovan ser annorlunda ut än den i det ursprungliga forskningsdokumentet. De nya symbolerna kan ses i Tabell 2:
ytterligare två variabler $i$ och $j$, betyder ”vid ursprungspunkt” respektive ”vid London”. $Wa_{i}$ betyder ” lönenivåer vid ursprungspunkten ”medan $Wa_{j}$ skulle betyda”lönenivåer i London”. Dessa sju nya symboler kan ersätta de mer generiska i formeln:
\
Detta är nu mer verbose och en något självdokumenterad version av föregående ekvation. Båda löser matematiskt på exakt samma sätt, eftersom förändringarna är rent ytliga och till förmån för en mänsklig användare.
den färdiga Variabeldatasatsen
för att göra handledningen snabbare lättare att slutföra har data för var och en av de 5 variablerna och var och en av de 32 länen redan sammanställts och rengjorts och kan ses i tabell 3 eller laddas ner som en csv-fil. Denna tabell innehåller också det kända antalet vandrare från det länet, som observerats i den primära källposten:
| län | lösdrivare | $ d $ km till London | $P$ befolkning (personer) | $ Wa $ Genomsnittslön (shilling) | $WaT $ lön bana 1767-95 (% förändring) | $Wh$ vete pris (shilling) |
|---|---|---|---|---|---|---|
| Bedfordshire | 26 | 61.9 | 54836 | 87 | 1.149 | 61.79 |
| Berkshire | 111 | 61.7 | 101939 | 90 | 4.44 | 63.07 |
| Buckinghamshire | 79 | 46.7 | 95936 | 96 | -8.33 | 63.09 |
| Cambridgeshire | 32 | 86.8 | 80497 | 88 | 11.36 | 60.05 |
| Cheshire | 34 | 255.1 | 158038 | 80 | 35.00 | 69.19 |
| Cornwall | 40 | 364.6 | 142179 | 81 | 14.81 | 67.94 |
| Cumberland | 13 | 407.3 | 96862 | 78 | 38.46 | 64.42 |
| Derbyshire | 28 | 196.9 | 122593 | 75 | 48.00 | 68.02 |
| Devon | 98 | 272.5 | 279652 | 89 | -7.87 | 69.98 |
| Dorset | 27 | 176.8 | 97262 | 81 | 22.22 | 67.30 |
| Durham | 25 | 380.7 | 119779 | 78 | 33.33 | 63.16 |
| Gloucestershire | 162 | 157.1 | 215576 | 81 | 9.88 | 66.54 |
| Hampshire | 78 | 102.4 | 166648 | 96 | 6.25 | 61.45 |
| Herefordshire | 45 | 190.5 | 81882 | 70 | 28.57 | 62.05 |
| Hertfordshire | 99 | 35.3 | 95868 | 90 | 4.44 | 63.82 |
| Huntingdonshire | 21 | 87.5 | 35370 | 89 | 7.87 | 58.72 |
| Lancashire | 94 | 281.8 | 301407 | 78 | 55.13 | 71.65 |
| Leicestershire | 20 | 146.1 | 107028 | 79 | 65.82 | 64.84 |
| Lincolnshire | 41 | 179.8 | 181814 | 84 | 26.19 | 58.73 |
| Northamptonshire | 33 | 107.6 | 128798 | 78 | 21.79 | 63.81 |
| Northumberland | 58 | 440.0 | 148148 | 72 | 70.83 | 58.22 |
| Nottinghamshire | 31 | 187.5 | 98216 | 108 | 0.00 | 61.30 |
| Oxfordshire | 78 | 86.8 | 99354 | 84 | 25.00 | 64.23 |
| Rutland | 2 | 132.5 | 15123 | 90 | 10.00 | 64.12 |
| Shropshire | 75 | 214.0 | 147303 | 76 | 18.42 | 66.50 |
| Somerset | 159 | 180.4 | 234179 | 77 | 3.90 | 68.29 |
| Staffordshire | 82 | 185.3 | 175075 | 76 | 18.42 | 67.80 |
| Warwickshire | 104 | 149.3 | 152050 | 96 | -3.13 | 65.05 |
| Westmorland | 5 | 365.0 | 38342 | 74 | 62.16 | 71.05 |
| Wiltshire | 99 | 131.7 | 182421 | 84 | 20.24 | 63.64 |
| Worcestershire | 94 | 164.4 | 130757 | 81 | 25.93 | 65.78 |
| Yorkshire | 127 | 282.2 | 651709 | 80 | 58.33 | 61.87 |
den slutliga skillnaden mellan denna formel och den som används i den ursprungliga artikeln är att två av variablerna råkar ha ett starkare förhållande till vagrancy när de plottas naturligt logaritmiskt. De är befolkning vid ursprung ($P$) och avstånd från ursprung till London ($d$). Vad detta betyder är att för data i denna studie är regressionslinjen (ibland kallad linje med bästa passform) En bättre passform när data har loggats än när den inte har varit. Du kan se detta i Figur 7, med de icke-loggade populationssiffrorna till vänster och den loggade versionen till höger. Fler av punkterna är närmare linjen med bästa passform på den loggade grafen än på den icke-loggade.
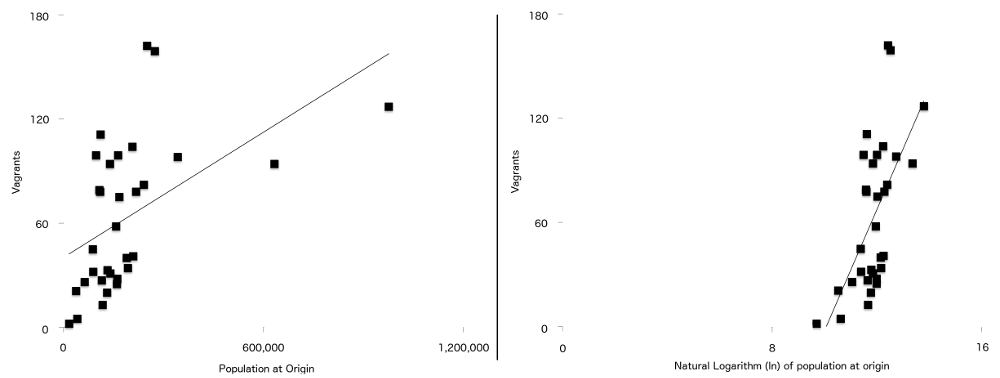
Figur 7: Antal Vagrants plottade mot befolkning vid ursprung (vänster) och naturlig logg över ursprungsbefolkning (höger) med en enkel regressionslinje överlagrad på båda. Observera det starkare förhållandet mellan de två variablerna som är synliga i den andra grafen.
eftersom detta är fallet med denna speciella data (dina egna data i en liknande typ av studie kanske inte följer detta mönster) justerades formeln för att använda de naturligt loggade versionerna av dessa två variabler, vilket resulterade i den slutliga formeln som användes i gravitationsmodellen (figur 8). Vi kunde omöjligt ha vetat om behovet av denna justering förrän vi hade samlat in våra variabla data:
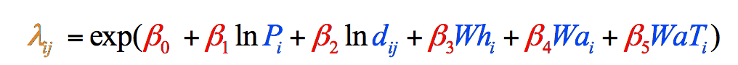
figur 8: Den slutliga gravitationsmodellformeln uppdelad i steg och färgkodad. Element i svart är matematiska operationer. Element i blått representerar våra variabler, som vi just har samlat (Steg 1). Element i rött representerar viktningarna för varje variabel, som vi måste beräkna (steg 2), och elementet i Orange är den slutliga uppskattningen av vagrants från det länet, som vi kan beräkna när vi har den andra informationen (steg 3).
värdena i tabell 3 ger oss allt vi behöver för att fylla i de blå delarna av varje ekvation i Figur 8. Vi kan nu rikta vår uppmärksamhet mot de röda delarna, som berättar hur viktig varje variabel är i modellen totalt sett och ger oss de siffror vi behöver för att slutföra ekvationen.
steg 2: Bestämning av viktningarna
viktningarna för varje variabel berättar hur viktigt den push/pull-faktorn är i förhållande till de andra variablerna när man försöker uppskatta antalet vagrants som borde ha kommit från ett visst län. Parametrarna för $ USD $ måste bestämmas över hela datamängden från kända data. Med dessa till hands kommer vi att kunna jämföra enskilda ursprungsspecifika observationer med den allmänna modellen. Vi kan sedan undersöka dessa och identifiera över och under förutsagda flöden mellan de olika ursprung och destination.
i detta skede vet vi inte hur viktigt var och en är. Kanske vete pris är en bättre prediktor för migration än avstånd? Vi kommer inte att veta förrän vi beräknar värdena på $ 1 $ till $ 5 $ (viktningarna) genom att lösa ekvationen ovan. Y-intercept ($20$) kan bara beräknas när du känner till alla andra ($1-5$$). Dessa är de röda värdena i Figur 8 ovan. Viktningarna kan ses i Tabell 4 och i tabell A1 i originalpapperet.16 vi ska nu visa hur vi kom till dessa värden.
för att beräkna dessa värden lång hand kräver en otrolig mängd arbete. Vi kommer att använda en snabb lösning i r-programmeringsspråket som utnyttjar William Venables och Brian Ripleys MASSPAKET som kan lösa negativa binomiala regressionsekvationer som vår gravitationsmodell med en enda kodrad. Det är dock viktigt att förstå principerna bakom vad man gör för att uppskatta vad koden gör (notera följande avsnitt gör inte beräkningen, men förklara dess steg för dig; vi kommer att göra beräkningen med koden längre ner på sidan).
beräkning av de enskilda viktningarna (i princip)
$usci_{1}$, $usci_{2}$, etc, är samma som $usci$ i den enkla linjära regressionsmodellen ovan, vilket är regressionslinjens lutning (ökningen över körningen, eller hur mycket $y$ ökar när $x$ ökar med 1). Den enda skillnaden här mellan en enkel linjär Regression och vår gravitationsmodell är att vi måste beräkna 5 sluttningar istället för 1.
en enkel linjär Regression\(y = 2727 + xnumx\)
vi måste lösa för var och en av dessa fem sluttningar innan vi kan beräkna y-avlyssningen i nästa steg. Det beror på att sluttningarna av de olika $ USD $ – värdena är en del av ekvationen för beräkning av y-intercept.
formeln för beräkning av $ USD $ i en regressionsanalys är:
\
Pearsons korrelationskoefficient
Pearsons korrelationskoefficient kan beräknas långhand men det är en ganska lång beräkning i detta fall, vilket kräver 64 siffror. Det finns några bra video tutorials på engelska tillgängliga online om du vill se en genomgång av hur man gör beräkningarna lång hand.17 Det finns också ett antal onlinekalkylatorer som beräknar $r$ åt dig om du tillhandahåller uppgifterna. Med tanke på det stora antalet siffror att beräkna, skulle jag rekommendera en webbplats med ett inbyggt verktyg för att göra denna beräkning. Se till att du väljer en ansedd webbplats, till exempel en som erbjuds av ett universitet.
beräkning av $s_{y}$& $s_{x}$ (standardavvikelse)
standardavvikelse är ett sätt att uttrycka hur mycket variation från medelvärdet (genomsnittet) det finns i data. Med andra ord, är uppgifterna ganska grupperade kring medelvärdet, eller är spridningen mycket bredare?
återigen finns det onlinekalkylatorer och statistiska mjukvarupaket som kan göra denna beräkning för dig om du tillhandahåller uppgifterna.
beräkning av $expor_{0}$ (y-Intercept)
Därefter måste vi beräkna y-intercept. Formeln för beräkning av y-interceptet i en enkel linjär Regression är:
\
beräkningen blir emellertid mycket mer komplicerad i en multipel regressionsanalys, eftersom varje variabel påverkar beräkningen. Detta gör det mycket svårt att göra det för hand och är en av anledningarna till att vi väljer en programmatisk lösning.
koden för beräkning av viktningarna
MASSSTATISTIKPAKETET, skrivet för R-programmeringsspråket, har en funktion som kan lösa negativa binomiala regressionsekvationer, vilket gör det mycket enkelt att beräkna vad som annars skulle vara en mycket svår långhandsformel.
det här avsnittet förutsätter att du har installerat R och har installerat MASSPAKETET. Om du inte har gjort det måste du innan du fortsätter. Taryn Dewar handledning om r grunderna med tabelldata innehåller r installationsanvisningar.
för att använda den här koden måste du ladda ner en kopia av datauppsättningen för de fem variablerna plus antalet observerade vagrants från vart och ett av de 32 länen. Detta finns ovan som Tabell 3, eller kan laddas ner som en .csv-fil. Oavsett vilket läge du väljer, spara filen som VagrantsExampleData.csv. Om du använder en Mac, se till att du sparar den som ett Windows-format .csv-fil. Öppna VagrantsExampleData.csv och bekanta dig med innehållet. Du bör märka var och en av de 32 länen, tillsammans med var och en av de variabler som vi har diskuterat under hela denna handledning. Vi kommer att använda kolumnrubrikerna för att komma åt dessa data med vårt datorprogram. Jag kunde ha kallat dem vad som helst, men i den här filen är de:
vagrantspopulationdistancewheatwageswageTrajectory
i samma katalog som du sparade csv-filen, skapa och spara en ny r-skriptfil (du kan göra det med valfri textredigerare eller Med RStudio, men använd inte en ordbehandlare som MS Word). Spara det som viktningarberäkningar.r.
vi kommer nu att skriva ett kort program som:
- installerar MASSPAKETET
- kallar MASSPAKETET så att vi kan använda det i vår kod
- lagrar innehållet i .csv-fil till en variabel som vi kan använda programmatiskt
- löser gravitationsmodellekvationen med hjälp av datasetet
- matar ut resultaten av beräkningen.
var och en av dessa uppgifter kommer att uppnås i sin tur med en enda rad kod
kopiera ovanstående kod till dina viktningarberäkningar.r-fil och spara. Du kan nu köra koden med din favorit r-miljö (jag använder RStudio) och resultaten av beräkningen ska visas i konsolfönstret (hur det ser ut beror på din miljö). Du kan behöva ställa in arbetskatalogen för din r-miljö till katalogen som innehåller din .csv och .r-filer. Om du använder RStudio kan du göra det via menyerna (Session – > Ställ in arbetskatalog – > Välj katalog). Du kan också uppnå samma sak med kommandot:
setwd(PATH) #change "PATH" to the full location on your computer where the files can be foundLägg märke till att linje 4 är den linje som löser ekvationen för oss, med hjälp av glm.nb-funktion, som är förkortning för”generaliserad linjär modell – negativ binomial”. Denna linje kräver ett antal ingångar:
- våra variabler använder kolumnrubrikerna som skrivna i .csv-fil, tillsammans med någon loggning som måste göras för dem (
vagrants, log (population), log(distance),wheat,wages,wageTrajectory). Om du körde en modell med dina egna data skulle du justera dessa för att återspegla dina kolumnrubriker i din dataset. - där koden kan hitta data-i det här fallet en variabel som vi har definierat i rad 3 som heter
gravityModelData.
utgångarna från beräkningen kan ses i Figur 9:
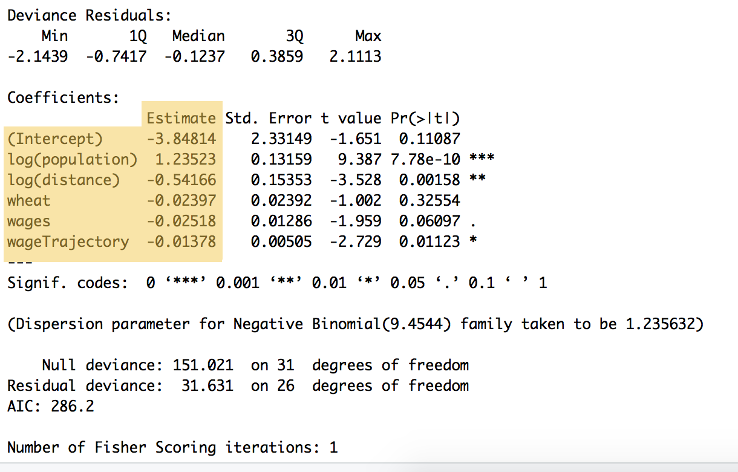
Figur 9: sammanfattningen av ovanstående kod, som visar viktningarna för varje variabel och y-intercept, listad under rubriken ’uppskattning’ ($\beta_{0}$ till $\beta_{5}$. Denna sammanfattning visar också ett antal andra beräkningar, inklusive statistisk signifikans.
steg 3: Beräkning av uppskattningarna för varje län
vi måste göra detta en gång för var och en av de 32 länen.
du kan göra detta med en vetenskaplig kalkylator, genom att skapa ett kalkylblad formel, eller skriva ett datorprogram. För att göra detta automatiskt i R kan du lägga till följande i din kod och köra programmet igen. Denna for loop beräknar det förväntade antalet vagrants från var och en av de 32 länen i exemplet och skriver ut resultaten för att du ska se:
för att bygga förståelse föreslår jag att du gör ett län långhand. Denna handledning kommer att använda Hertfordshire som långhandsexemplet (men processen är exakt densamma för de andra 31 länen).
med hjälp av data för Hertfordshire i tabell 3 och viktningarna för varje variabel i Tabell 4 kan vi nu slutföra vår formel, som ger resultatet av 95:
låt oss först byta ut symbolerna för siffrorna, tagna från tabellerna som nämns ovan.
börja sedan beräkna värden för att komma till uppskattningen. Kom ihåg matematisk ordning av operationer, multiplicera värden innan du lägger till. Så börja med att beräkna varje variabel (du kan använda en vetenskaplig kalkylator för detta):
nästa steg är att lägga till siffrorna tillsammans:
estimated vagrants = exp(4.56232408897)och slutligen, för att beräkna exponentiell funktion (använd en vetenskaplig kalkylator):
estimated vagrants = 95.8059926832vi har tappat resten och förklarat att det uppskattade antalet vagrants från Hertfordshire i denna modell är 95. Du måste göra samma beräkningar för var och en av de andra länen, som du kan påskynda med hjälp av ett kalkylprogram. Bara för att se till att du kan göra det igen har jag också inkluderat siffrorna för Buckinghamshire:
Hertfordshire
\
Buckinghamshire
\
jag rekommenderar att du väljer ett annat län och beräknar det långt innan du går vidare, för att se till att du kan göra beräkningarna på egen hand. Det rätta svaret finns i Tabell 5, som jämför de observerade värdena (som ses i den primära källposten) med de uppskattade värdena (som beräknas av vår gravitationsmodell). Den ”återstående” är skillnaden mellan de två, med en stor skillnad som tyder på ett oväntat antal vagrants som kan vara värda en närmare titt med en historikers hatt på.
| Län | Observerat Värde | Uppskattat Värde | Restvärde |
|---|---|---|---|
| Bedfordshire | 26 | 41 | -15 |
| Berkshire | 111 | 76 | 35 |
| Buckinghamshire | 79 | 83 | -4 |
| Cambridgeshire | 32 | 48 | -16 |
| Cheshire | 34 | 44 | -10 |
| Cornwall | 40 | 42 | -2 |
| Cumberland | 13 | 21 | -8 |
| Derbyshire | 28 | 36 | -8 |
| Devon | 98 | 121 | -23 |
| Dorset | 27 | 36 | -9 |
| Durham | 25 | 31 | -6 |
| Gloucestershire | 162 | 123 | 39 |
| Hampshire | 78 | 92 | -14 |
| Herefordshire | 45 | 39 | 6 |
| Hertfordshire | 99 | 95 | 4 |
| Huntingdonshire | 21 | 18 | 3 |
| Lancashire | 94 | 84 | 10 |
| Leicestershire | 20 | 28 | -8 |
| Lincolnshire | 41 | 86 | -45 |
| Northamptonshire | 33 | 78 | -45 |
| Northumberland | 58 | 29 | 29 |
| Nottinghamshire | 31 | 28 | 3 |
| Oxfordshire | 78 | 52 | 26 |
| Rutland | 2 | 4 | -2 |
| Shropshire | 75 | 66 | 9 |
| Somerset | 159 | 145 | 14 |
| Staffordshire | 82 | 85 | -3 |
| Warwickshire | 104 | 70 | 34 |
| Westmorland | 5 | 5 | 0 |
| Wiltshire | 99 | 95 | 4 |
| Worcestershire | 94 | 53 | 41 |
| Yorkshire | 127 | 207 | -80 |
steg 4-Historisk Tolkning
i detta skede är modelleringsprocessen klar och slutskedet är Historisk Tolkning.
den ursprungliga publicerade artikeln som denna fallstudie baserades på ägnas främst åt att tolka vad resultaten av modelleringen betyder för vår förståelse av lägre klassmigration i artonhundratalet. Som framgår av kartan i Figur 5, det fanns delar av landet som modellen starkt föreslog var antingen över – eller under-skicka lägre klass migranter till London.
medförfattarna erbjöd sina tolkningar om varför dessa mönster kan ha dykt upp. Dessa tolkningar varierade efter plats. I områden i norra England som snabbt industrialiserades, såsom Yorkshire eller Manchester, tycktes möjligheterna lokalt ge människor färre skäl att lämna, vilket resulterade i lägre migration än väntat till London. I sjunkande områden i väster, såsom Bristol, drag av London var starkare eftersom fler människor kvar söker arbete i huvudstaden.
inte alla mönster förväntades. Northumberland i fjärran nordöstra visade sig vara en regional anomali och skickade mycket fler (kvinnliga) migranter till London än vi förväntar oss att se. Utan modellens resultat är det osannolikt att vi skulle ha tänkt att överväga Northumberland alls, särskilt för att det var så långt från metropolen och vi antog skulle ha svaga band till London. Modellen gav således nya bevis för oss att betrakta som historiker och förändrade vår förståelse för förhållandet mellan London och Northumberland. En fullständig diskussion om våra resultat kan läsas i den ursprungliga artikeln.18
ta din kunskap framåt
efter att ha provat detta exempelproblem bör du ha en klar förståelse för hur du använder denna exempelformel, samt huruvida en gravitationsmodell kan vara en lämplig lösning för ditt forskningsproblem. Du har erfarenhet och ordförråd att närma sig och diskutera gravitationsmodeller med en lämpligt matematiskt läskunnig medarbetare om du behöver, som kan hjälpa dig att anpassa den till din egen fallstudie.
om du har turen att också ha data om migranter som flyttar till slutet av artonhundratalet London och du vill modellera det med samma fem variabler som anges ovan, skulle denna formel fungera som det är-det finns en enkel studie här för någon med rätt data. Denna modell fungerar dock inte bara för studier om migranter som flyttar till London. Variablerna kan ändras, och destinationen behöver inte vara London. Det skulle vara möjligt att använda en gravitationsmodell för att studera migration till antika Rom, eller tjugoförsta århundradet Bangkok, om du har data och forskningsfrågan. Det behöver inte ens vara en modell för migration. För att använda den colombianska kaffefallstudien från introduktionen, som fokuserar på handel snarare än migration, visar tabell 6 en livskraftig användning av samma formel, oförändrad.
| kriterier | exempel på kaffeexport |
|---|---|
| en ursprungspunkt | kaffeexport från hamnen i Barranquilla, Colombia |
| flera ändliga destinationer | de 21 länderna på västra halvklotet i 1950 |
| fem förklarande variabler | (1) Antal hamnar i Atlanten i mottagarlandet (2) mil från Colombia, (3) mottagarlandets bruttonationalprodukt, (4) inhemskt kaffe odlat i ton, (5) kaffebutiker per 10 000 personer |
det finns en lång historia av gravitationsmodeller i akademiskt stipendium. För att använda en effektivt för forskning måste du förstå den grundläggande teorin och matematiken bakom dem och orsakerna till att de har utvecklats som de har. Det är också viktigt att förstå deras gränser och villkor för att använda dem ordentligt, varav några diskuterades ovan. Det kan också hjälpa att veta:
-
en gravitationsmodell som den som används i detta exempel kan bara fungera i ett slutet system. Ovanstående modell hade endast 32 möjliga ursprungspunkter, vilket gjorde det möjligt att köra modellen 32 gånger. Ett okänt eller oändligt stort antal ursprungspunkter (eller destinationer beroende på din modell) skulle kräva en annan ekvation.
-
gravitationsmodellkonceptet bygger också på förutsättningen att rörelser (migration, handel etc.) bygger på en samling frivilliga individuella beslut som kan påverkas av yttre faktorer, men inte helt kontrolleras av dem. Till exempel kan frivilliga migrationer eller inköp av fri vilja modelleras med hjälp av denna teknik, men tvångsmigration, tvångsinköp eller naturliga processer som fågelmigration eller flodflöde kanske inte följer samma principer och därför kan en annan typ av modell behövas.
-
Gravity modeller kan användas för att förutsäga beteendet hos populationer men inte individer, och därför försök att modellera data bör innehålla ett stort antal rörelser för att säkerställa statistisk signifikans.
det finns många fler fallgropar, men också enorma möjligheter. Det är mitt hopp att denna genomgång av en gravitationsmodell, och dess medföljande publicerade forskning, kommer att göra detta kraftfulla verktyg mer tillgängligt för historiker. Om du planerar att använda en gravitationsmodell i din vetenskapliga forskning rekommenderar författaren starkt följande artiklar:
bekräftelser
med tack till Angela Kedgley, Sarah Lloyd, Tim Hitchcock, Joe Cozens, Katrina Navickas och Leanne Calvert för att läsa och kommentera tidigare utkast till denna artikel. Också tack till den brittiska akademin för finansiering av skrivverkstaden i Bogot Brasilien, Colombia där denna artikel utarbetades. Och slutligen till Adam Dennett för att introducera mig till dessa underbara formler och frigöra deras potential för historiker.