Senast uppdaterad den 7 augusti 2019
Word-inbäddning är en typ av ordrepresentation som tillåter ord med liknande betydelse att ha en liknande representation.
de är en distribuerad representation för text som kanske är ett av de viktigaste genombrotten för den imponerande prestandan av djupa inlärningsmetoder på utmanande problem med naturlig språkbehandling.
i det här inlägget kommer du att upptäcka ordet inbäddningsmetod för att representera textdata.
när du har slutfört det här inlägget kommer du att veta:
- vad ordet inbäddning metod för att representera text är och hur det skiljer sig från andra funktioner extraktionsmetoder.
- att det finns 3 huvudalgoritmer för att lära sig ett ord inbäddning från textdata.
- att du antingen kan träna en ny inbäddning eller använda en förutbildad inbäddning på din naturliga språkbehandlingsuppgift.
Kick-starta ditt projekt med min nya bok Deep Learning för naturlig språkbehandling, inklusive steg-för-steg-handledning och Python-källkodsfilerna för alla exempel.
Låt oss komma igång.

Vad är Word-inbäddning för Text?
foto av Heather, vissa rättigheter reserverade.
- översikt
- behöver du hjälp med Deep Learning för textdata?
- Vad är Word-inbäddning?
- Word Embedding Algorithms
- Inbäddningslager
- Word2Vec
- handske
- använda Word-inbäddningar
- lär dig en inbäddning
- Återanvänd en inbäddning
- Vilket Alternativ Ska Du Använda?
- Word inbäddning Tutorials
- Vidare läsning
- artiklar
- papper
- projekt
- böcker
- sammanfattning
- utveckla djupa inlärningsmodeller för textdata idag!
- utveckla dina egna Textmodeller på några minuter
- slutligen ta djupt lärande till dina naturliga Språkbehandlingsprojekt
översikt
detta inlägg är uppdelat i 3 delar; de är:
- Vad är Word Embeddings?
- Word-Inbäddningsalgoritmer
- använda Word-inbäddningar
behöver du hjälp med Deep Learning för textdata?
ta min gratis 7-dagars e-postkraschkurs nu (med kod).
Klicka för att registrera dig och få en gratis PDF-e-bokversion av kursen.
starta din gratis kraschkurs nu
Vad är Word-inbäddning?
ett ordinbäddning är en lärd representation för text där ord som har samma betydelse har en liknande representation.
det är detta sätt att representera ord och dokument som kan betraktas som ett av de viktigaste genombrotten i djupt lärande om utmanande problem med naturlig språkbehandling.
en av fördelarna med att använda täta och lågdimensionella vektorer är beräkning: majoriteten av neurala nätverksverktyg spelar inte bra med mycket högdimensionella, glesa vektorer. … Den största fördelen med de täta representationerna är generaliseringskraft: om vi tror att vissa funktioner kan ge liknande ledtrådar är det värt att ge en representation som kan fånga dessa likheter.
— sida 92, neurala Nätverksmetoder i naturlig språkbehandling, 2017.
Ordinbäddningar är i själva verket en klass av tekniker där enskilda ord representeras som verkliga värderade vektorer i ett fördefinierat vektorutrymme. Varje ord mappas till en vektor och vektorvärdena lärs på ett sätt som liknar ett neuralt nätverk, och därför klumpas tekniken ofta in i fältet för djupt lärande.
nyckeln till tillvägagångssättet är tanken på att använda en tät distribuerad representation för varje ord.
varje ord representeras av en realvärderad vektor, ofta tiotals eller hundratals dimensioner. Detta står i kontrast till de tusentals eller miljoner dimensioner som krävs för glesa ordrepresentationer, till exempel en en-het kodning.
associera med varje ord i ordförrådet en distribuerad Word feature vector … funktionsvektorn representerar olika aspekter av ordet: varje ord är associerat med en punkt i ett vektorutrymme. Antalet funktioner … är mycket mindre än ordförrådets storlek
— en Neural probabilistisk Språkmodell, 2003.
den distribuerade representationen lärs ut baserat på användningen av ord. Detta gör att ord som används på liknande sätt kan resultera i liknande representationer och naturligtvis fånga deras betydelse. Detta kan kontrasteras med den skarpa men bräckliga representationen i en påse med ord modell där, om inte uttryckligen hanteras, olika ord har olika representationer, oavsett hur de används.
det finns djupare språkteori bakom tillvägagångssättet, nämligen” fördelningshypotesen ” av Zellig Harris som kan sammanfattas som: ord som har liknande sammanhang kommer att ha liknande betydelser. För mer djup se Harris ’1956 papper”Fördelningsstruktur”.
denna uppfattning om att låta användningen av ordet definiera dess betydelse kan sammanfattas av en ofta upprepad quip av John Firth:
du ska veta ett ord av företaget det håller!
— sidan 11,” en sammanfattning av språkteori 1930-1955″, i studier i språklig analys 1930-1955, 1962.
Word Embedding Algorithms
Word embedding methods lär dig en realvärderad vektorrepresentation för ett fördefinierat ordförråd med fast storlek från en korpus av text.
inlärningsprocessen är antingen gemensam med neurala nätverksmodellen på någon uppgift, till exempel dokumentklassificering, eller är en oövervakad process med hjälp av dokumentstatistik.
detta avsnitt granskar tre tekniker som kan användas för att lära sig ett ord inbäddning från textdata.
Inbäddningslager
ett inbäddningslager, i brist på ett bättre namn, är ett ordinbäddning som lärs gemensamt med en neuralt nätverksmodell på en specifik naturlig språkbehandlingsuppgift, till exempel språkmodellering eller dokumentklassificering.
det kräver att dokumenttext ska rengöras och förberedas så att varje ord är en-het kodad. Storleken på vektorutrymmet anges som en del av modellen, till exempel 50, 100 eller 300 dimensioner. Vektorerna initieras med små slumptal. Inbäddningsskiktet används på framsidan av ett neuralt nätverk och passar på ett övervakat sätt med hjälp av Backpropagationalgoritmen.
… när ingången till ett neuralt nätverk innehåller symboliska kategoriska funktioner (t. ex. funktioner som tar en av k distinkta symboler, till exempel ord från ett slutet ordförråd), är det vanligt att associera varje möjligt funktionsvärde (dvs. varje ord i ordförrådet) med en d-dimensionell vektor för vissa d. dessa vektorer betraktas sedan som parametrar för modellen och tränas tillsammans med de andra parametrarna.
— sida 49, neurala Nätverksmetoder i naturlig språkbehandling, 2017.
de en-heta kodade orden mappas till ordvektorerna. Om en flerskiktsperceptron-modell används, sammanfogas ordvektorerna innan de matas som inmatning till modellen. Om ett återkommande neuralt nätverk används, kan varje ord tas som en ingång i en sekvens.
denna metod för att lära sig ett inbäddningslager kräver mycket träningsdata och kan vara långsam, men kommer att lära sig en inbäddning både riktad mot specifika textdata och NLP-uppgiften.
Word2Vec
Word2Vec är en statistisk metod för att effektivt lära sig ett fristående ord inbäddning från en text corpus.
det utvecklades av Tomas Mikolov, et al. på Google 2013 som ett svar för att göra den neurala nätverksbaserade träningen av inbäddning effektivare och sedan dess har blivit de facto-standarden för att utveckla förutbildad inbäddning av ord.
dessutom involverade arbetet analys av de lärda vektorerna och utforskningen av vektormatematik på representationer av ord. Till exempel, att subtrahera ”man-ness” från ”kung” och lägga till ”kvinnor-ness” resulterar i ordet ”drottning”, fånga analogin ”kung är till drottning som man är till kvinna”.
vi finner att dessa representationer är förvånansvärt bra på att fånga syntaktiska och semantiska regelbundenheter i språket, och att varje relation kännetecknas av en relationsspecifik vektorförskjutning. Detta möjliggör vektororienterad resonemang baserat på förskjutningarna mellan ord. Till exempel lärs förhållandet mellan man och kvinna automatiskt, och med de inducerade vektorrepresentationerna resulterar ”King – Man + Woman” i en vektor mycket nära ”Queen.”
— språkliga regelbundenheter i kontinuerliga Rymdordrepresentationer, 2013.
två olika inlärningsmodeller introducerades som kan användas som en del av word2vec-metoden för att lära sig ordet inbäddning; de är:
- kontinuerlig Bag-Of-ord, eller CBOW modell.
- Kontinuerlig Skip-Gram Modell.
CBOW-modellen lär sig inbäddningen genom att förutsäga det aktuella ordet baserat på dess sammanhang. Den kontinuerliga skip-gram-modellen lär sig genom att förutsäga de omgivande orden som ges ett aktuellt ord.
den kontinuerliga skip-gram-modellen lär sig genom att förutsäga de omgivande orden som ges ett aktuellt ord.
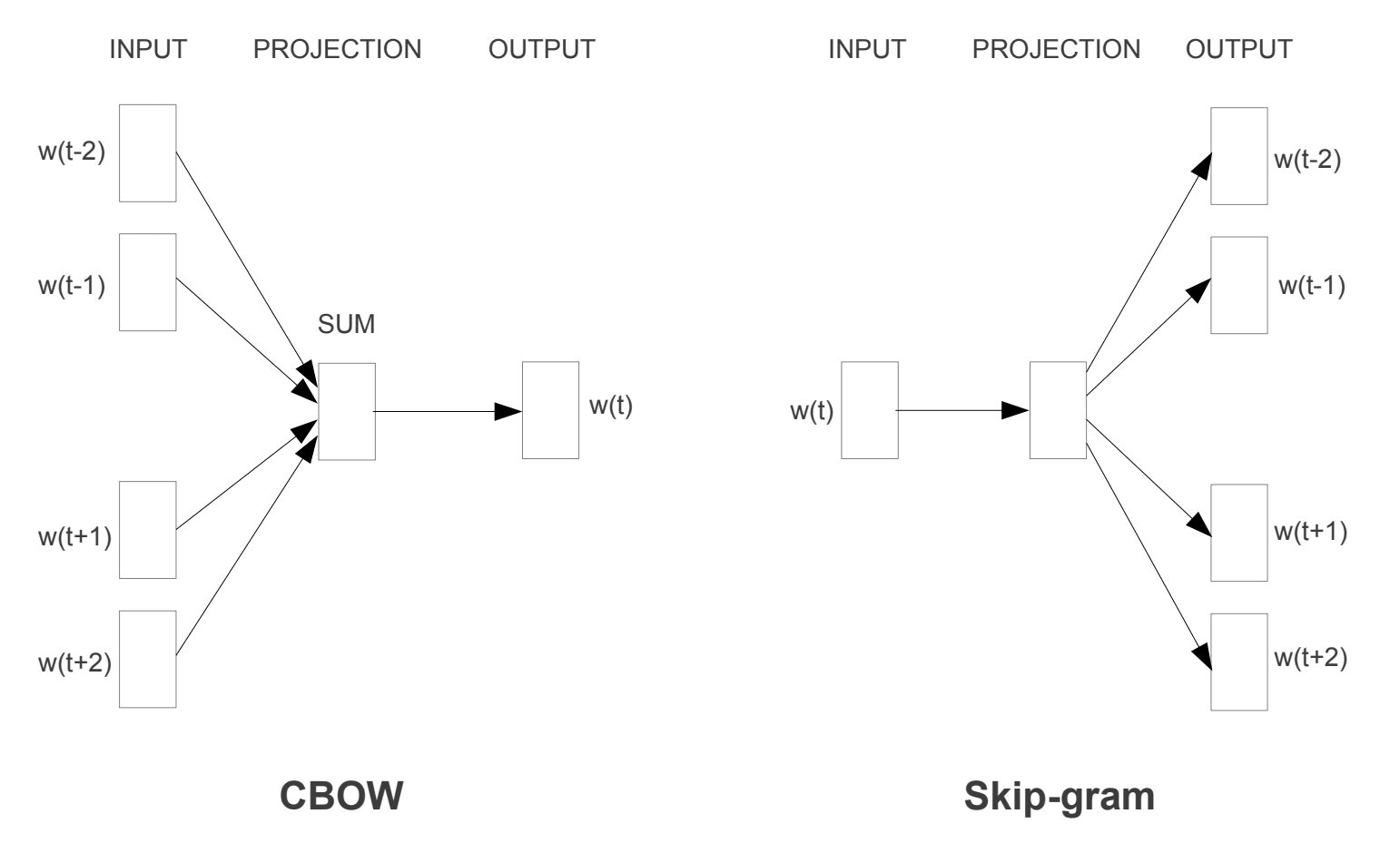
Word2Vec träningsmodeller
hämtad från ”effektiv uppskattning av Ordrepresentationer i vektorutrymme”, 2013
båda modellerna är inriktade på att lära sig om ord med tanke på deras lokala användningskontext, där sammanhanget definieras av ett fönster med angränsande ord. Detta fönster är en konfigurerbar parameter för modellen.
storleken på skjutfönstret har en stark effekt på de resulterande vektorlikheterna. Stora fönster tenderar att producera mer aktuella likheter, medan mindre fönster tenderar att producera mer funktionella och syntaktiska likheter.
— sida 128, neurala Nätverksmetoder i naturlig språkbehandling, 2017.
den viktigaste fördelen med tillvägagångssättet är att högkvalitativa ordinbäddningar kan läras effektivt (låg rymd-och tidskomplexitet), vilket gör att större inbäddningar kan läras (fler dimensioner) från mycket större korpusar av text (miljarder ord).
handske
de globala vektorerna för Ordrepresentation, eller handske, algoritm är en förlängning till word2vec-metoden för effektiv inlärning av ordvektorer, utvecklad av Pennington, et al. på Stanford.
klassiska vektorrymdmodellrepresentationer av ord utvecklades med hjälp av matrisfaktoriseringstekniker som Latent semantisk analys (LSA) som gör ett bra jobb med att använda global textstatistik men inte är lika bra som de lärda metoderna som word2vec för att fånga mening och demonstrera det på uppgifter som att beräkna analogier (t. ex. kungen och drottningen exemplet ovan).
GloVe är ett sätt att gifta sig med både den globala statistiken över matrisfaktoriseringstekniker som LSA med det lokala kontextbaserade lärandet i word2vec.
i stället för att använda ett fönster för att definiera lokala sammanhang, handske konstruerar en explicit word-sammanhang eller word co-förekomst matris med hjälp av statistik över hela texten corpus. Resultatet är en inlärningsmodell som kan resultera i generellt bättre ordinbäddning.
GloVe, är en ny global log-bilinär regressionsmodell för oövervakad inlärning av ordrepresentationer som överträffar andra modeller på ordanalogi, ordslikhet och namngivna entity recognition-uppgifter.
— handske: globala vektorer för Ordrepresentation, 2014.
använda Word-inbäddningar
du har några alternativ när det är dags att använda word-inbäddningar i ditt naturliga språkbehandlingsprojekt.
i det här avsnittet beskrivs dessa alternativ.
lär dig en inbäddning
du kan välja att lära dig ett ord inbäddning för ditt problem.
detta kommer att kräva en stor mängd textdata för att säkerställa att Användbara inbäddningar lärs, till exempel miljoner eller miljarder ord.
du har två huvudalternativ när du tränar ditt Word-inbäddning:
- lär det fristående, där en modell är utbildad för att lära sig inbäddning, som sparas och används som en del av en annan modell för din uppgift senare. Detta är ett bra tillvägagångssätt om du vill använda samma inbäddning i flera modeller.
- lär dig gemensamt, där inbäddning lärs som en del av en stor uppgiftsspecifik modell. Detta är ett bra tillvägagångssätt om du bara tänker använda inbäddning på en uppgift.
Återanvänd en inbäddning
det är vanligt att forskare gör förutbildade ordinbäddningar tillgängliga gratis, ofta under en tillåten licens så att du kan använda dem på dina egna akademiska eller kommersiella projekt.
till exempel är både word2vec och GloVe word-inbäddningar tillgängliga för gratis nedladdning.
dessa kan användas på ditt projekt istället för att träna dina egna inbäddningar från grunden.
du har två huvudalternativ när det gäller att använda förutbildade inbäddningar:
- statisk, där inbäddning hålls statisk och används som en del av din modell. Detta är ett lämpligt tillvägagångssätt om inbäddning passar bra för ditt problem och ger bra resultat.
- uppdaterad, där den förutbildade inbäddning används för att utsäde modellen, men inbäddning uppdateras gemensamt under utbildningen av modellen. Det här kan vara ett bra alternativ om du vill få ut det mesta av modellen och bädda in din uppgift.
Vilket Alternativ Ska Du Använda?
utforska de olika alternativen och om möjligt testa för att se vilka som ger bästa resultat på ditt problem.
kanske börja med snabba metoder, som att använda en förutbildad inbäddning, och använd bara en ny inbäddning om det resulterar i bättre prestanda på ditt problem.
Word inbäddning Tutorials
det här avsnittet listar några steg-för-steg tutorials som du kan följa för att använda word inbäddning och föra word inbäddning till ditt projekt.
- hur man utvecklar Word-inbäddningar i Python med Gensim
- hur man använder Word-Inbäddningslager för djupt lärande med Keras
- hur man utvecklar en djup CNN för sentimentanalys (Textklassificering)
Vidare läsning
det här avsnittet ger mer resurser om ämnet om du letar gå djupare.
artiklar
- Word inbäddning på Wikipedia
- Word2vec på Wikipedia
- handske på Wikipedia
- en översikt över word inbäddning och deras koppling till Distributions semantiska modeller, 2016.
- djupinlärning, NLP och representationer, 2014.
papper
- Fördelningsstruktur, 1956.
- En Neural Probabilistisk Språkmodell, 2003.
- en enhetlig arkitektur för naturlig språkbehandling: djupa neurala nätverk med Multitaskinlärning, 2008.
- kontinuerliga rymdspråkmodeller, 2007.
- effektiv uppskattning av Ordrepresentationer i Vektorrymden, 2013
- distribuerade representationer av ord och fraser och deras sammansättning, 2013.
- handske: globala vektorer för Ordrepresentation, 2014.
projekt
- word2vec på Google-kod
- handske: globala vektorer för Ordrepresentation
böcker
- neurala Nätverksmetoder i naturlig språkbehandling, 2017.
sammanfattning
i det här inlägget upptäckte du Word-inbäddning som en representationsmetod för text i djupa inlärningsapplikationer.
specifikt lärde du dig:
- vad ordet inbäddning tillvägagångssätt för representation text är och hur det skiljer sig från andra funktioner extraktionsmetoder.
- att det finns 3 huvudalgoritmer för att lära sig ett ord inbäddning från textdata.
- att du kan antingen träna en ny inbäddning eller använda en förutbildad inbäddning på din naturliga språkbehandlingsuppgift.
har du några frågor?
Ställ dina frågor i kommentarerna nedan och jag kommer att göra mitt bästa för att svara.
utveckla djupa inlärningsmodeller för textdata idag!

utveckla dina egna Textmodeller på några minuter
…med bara några rader med python-kod
Upptäck hur i min nya Ebook:
Deep Learning för naturlig språkbehandling
det ger självstudiehandledning om ämnen som:
Bag-of-Words, Word inbäddning, språkmodeller, Bildtextgenerering, textöversättning och mycket mer…
slutligen ta djupt lärande till dina naturliga Språkbehandlingsprojekt
hoppa över akademikerna. Bara Resultat.
se vad som finns inuti