Ci sono anche una serie di modi sbagliati per includere le variabili. Un modello di gravità non funzionerà a meno che ogni variabile soddisfi i seguenti criteri:
- Numerico
- Completo
- Affidabile
Solo dati numerici
Poiché il modello di gravità è un’equazione matematica, tutte le variabili di input devono essere numeriche. Questo potrebbe essere un conteggio (popolazione), misura spaziale (area, distanza, ecc.), tempo (ore da Londra a piedi), percentuale (aumento/diminuzione dei salari), valore valutario (salari in scellini) o qualche altra misura dei luoghi coinvolti nel modello.
I numeri devono essere significativi e non possono essere variabili categoriali nominali che fungono da stand-in per un attributo qualitativo. Ad esempio, non è possibile assegnare arbitrariamente un numero e utilizzarlo nel modello se il numero non ha significato (ad esempio, road quality = buono o road quality = 4). Sebbene quest’ultimo sia numerico, non è una misura della qualità della strada. Invece, è possibile utilizzare la velocità media di viaggio in miglia all’ora come proxy per la qualità della strada. Se la velocità media è una misura significativa della qualità della strada sta a voi determinare e difendere come l’autore dello studio.
In generale, se puoi misurarlo o contarlo, puoi modellarlo.
Dati completi Solo
Tutte le categorie di dati devono esistere per ogni punto di interesse. Ciò significa che tutte le contee 32 in analisi devono disporre di dati affidabili per ciascun fattore di spinta e trazione. Non puoi avere spazi vuoti o spazi vuoti, come una contea in cui non hai il salario medio.
Solo dati affidabili
L’adagio informatico “garbage in, garbage out” si applica anche ai modelli di gravità, che sono affidabili solo quanto i dati utilizzati per costruirli. Oltre a scegliere dati storici robusti e affidabili da fonti di cui ci si può fidare, ci sono molti modi per commettere errori che renderanno insignificanti gli output del modello. Ad esempio, vale la pena assicurarsi che i dati che hai corrispondano esattamente ai territori (ad esempio, i dati della contea per rappresentare le contee, non i dati della città per rappresentare una contea).
A seconda del tempo e del luogo dello studio, potrebbe risultare difficile ottenere un insieme affidabile di dati su cui basare il modello. Il più indietro nel passato uno studio, il più difficile che può essere. Allo stesso modo, può essere più facile condurre questi tipi di analisi in società che erano pesantemente burocratiche e hanno lasciato una buona traccia cartacea sopravvissuta, come in Europa o in Nord America.
Per garantire la qualità dei dati in questo caso di studio, ciascuna variabile è stata calcolata in modo affidabile o derivata da dati storici pubblicati sottoposti a revisione paritaria (cfr.Tabella 1). Esattamente come questi dati sono stati compilati può essere letto nell’articolo originale dove è stato spiegato in modo approfondito.11
- Le nostre cinque variabili modello
- Il set di dati delle variabili completato
- Passaggio 2: Determinazione delle ponderazioni
- Il codice per calcolare le ponderazioni
- Fase 3: Calcolando le stime per ogni contea
- Passo 4 – Interpretazione Storica
- Portare avanti le tue conoscenze
- Ringraziamenti
- Note di chiusura
Le nostre cinque variabili modello
Con i principi di cui sopra in mente, avremmo potuto scegliere qualsiasi numero di variabili, dato quello che sapevamo sulla migrazione push e pull fattori. Abbiamo optato per cinque (5), scelti in base a ciò che pensavamo sarebbe stato più importante e che sapevamo potesse essere eseguito il backup con dati affidabili.
| Variabile | Sorgente |
|---|---|
| popolazione all’origine | 1771 valori, Wrigley, “English county populations”, pp. 54-5.12 |
| distanza da Londra | calcolato con il software |
| prezzo del grano | Cannone e Brunt, “Settimanale Britannico dei Prezzi del Grano”13 |
| i salari medi all’origine | Caccia, “l’Industrializzazione e la Disuguaglianza Regionale”, pp. 965-6.14 |
| la traiettoria dei salari | Caccia, “l’Industrializzazione e la Disuguaglianza Regionale”, pp. 965-6.15 |
Tabella 1: Le cinque variabili utilizzate nel modello e la fonte di ciascuna nella letteratura peer reviewed
Avendo deciso su queste variabili, il coautore dello studio originale, Adam Dennett, ha deciso di riscrivere la formula per renderla auto-documentante in modo che fosse facile dire quali bit appartenevano a ciascuna di queste cinque variabili. Questo è il motivo per cui la formula mostrata sopra sembra diversa da quella nel documento di ricerca originale. I nuovi simboli possono essere visti nella Tabella 2:
Due variabili aggiuntive respectively i and e j j respectively, significano rispettivamente “al punto di origine” e “a Londra”. Wa Wa_ {i} means significa “livelli salariali nel punto di origine” mentre Wa Wa_ {j} mean significherebbe “livelli salariali a Londra”. Questi sette nuovi simboli possono sostituire quelli più generici nella formula:
\
Questa è ora più prolissa e una versione leggermente auto-documentata dell’equazione precedente. Entrambi risolvono matematicamente esattamente nello stesso modo, poiché i cambiamenti sono puramente superficiali e a beneficio di un utente umano.
Il set di dati delle variabili completato
Per rendere il tutorial più veloce e facile da completare, i dati per ciascuna delle 5 variabili e ciascuna delle 32 contee sono già stati compilati e puliti, e possono essere visualizzati nella Tabella 3 o scaricati come file csv. Questa tabella include anche il numero noto di vagabondi da quella contea, come osservato nel record di origine primaria:
| Contea | Vagabondi | $d$ km a Londra | $P$ di Popolazione (persone) | $Wa$ Salario Medio (scellini) | $WaT$ Salario Traiettoria 1767-95 (variazione%) | $Wh$ Prezzo del Grano (scellini) |
|---|---|---|---|---|---|---|
| Bedfordshire | 26 | 61.9 | 54836 | 87 | 1.149 | 61.79 |
| Berkshire | 111 | 61.7 | 101939 | 90 | 4.44 | 63.07 |
| Buckinghamshire | 79 | 46.7 | 95936 | 96 | -8.33 | 63.09 |
| Cambridgeshire | 32 | 86.8 | 80497 | 88 | 11.36 | 60.05 |
| Cheshire | 34 | 255.1 | 158038 | 80 | 35.00 | 69.19 |
| Cornovaglia | 40 | 364.6 | 142179 | 81 | 14.81 | 67.94 |
| Cumberland | 13 | 407.3 | 96862 | 78 | 38.46 | 64.42 |
| Derbyshire | 28 | 196.9 | 122593 | 75 | 48.00 | 68.02 |
| Devon | 98 | 272.5 | 279652 | 89 | -7.87 | 69.98 |
| Dorset | 27 | 176.8 | 97262 | 81 | 22.22 | 67.30 |
| Durham | 25 | 380.7 | 119779 | 78 | 33.33 | 63.16 |
| Gloucestershire | 162 | 157.1 | 215576 | 81 | 9.88 | 66.54 |
| Hampshire | 78 | 102.4 | 166648 | 96 | 6.25 | 61.45 |
| Herefordshire | 45 | 190.5 | 81882 | 70 | 28.57 | 62.05 |
| Hertfordshire | 99 | 35.3 | 95868 | 90 | 4.44 | 63.82 |
| Huntingdonshire | 21 | 87.5 | 35370 | 89 | 7.87 | 58.72 |
| Lancashire | 94 | 281.8 | 301407 | 78 | 55.13 | 71.65 |
| Leicestershire | 20 | 146.1 | 107028 | 79 | 65.82 | 64.84 |
| Lincolnshire | 41 | 179.8 | 181814 | 84 | 26.19 | 58.73 |
| Northamptonshire | 33 | 107.6 | 128798 | 78 | 21.79 | 63.81 |
| Northumberland | 58 | 440.0 | 148148 | 72 | 70.83 | 58.22 |
| Novara | 31 | 187.5 | 98216 | 108 | 0.00 | 61.30 |
| Oxfordshire | 78 | 86.8 | 99354 | 84 | 25.00 | 64.23 |
| Rutland | 2 | 132.5 | 15123 | 90 | 10.00 | 64.12 |
| Shropshire | 75 | 214.0 | 147303 | 76 | 18.42 | 66.50 |
| Somerset | 159 | 180.4 | 234179 | 77 | 3.90 | 68.29 |
| Staffordshire | 82 | 185.3 | 175075 | 76 | 18.42 | 67.80 |
| Warwickshire | 104 | 149.3 | 152050 | 96 | -3.13 | 65.05 |
| Westmorland | 5 | 365.0 | 38342 | 74 | 62.16 | 71.05 |
| Wiltshire | 99 | 131.7 | 182421 | 84 | 20.24 | 63.64 |
| Worcestershire | 94 | 164.4 | 130757 | 81 | 25.93 | 65.78 |
| Yorkshire | 127 | 282.2 | 651709 | 80 | 58.33 | 61.87 |
Il finale differenza tra questa formula e quello usato nell’articolo originale, è che due delle variabili capita di avere un rapporto più forte con il vagabondaggio quando tracciati naturalmente in modo logaritmico. Sono popolazione all’origine (P P)) e distanza dall’origine a Londra (d d d). Ciò significa che per i dati in questo studio, la linea di regressione (a volte chiamata linea di miglior adattamento) è più adatta quando i dati sono stati registrati rispetto a quando non lo sono stati. Potete vedere questo nella Figura 7, con le cifre della popolazione non registrate a sinistra e la versione registrata a destra. Più punti sono più vicini alla linea di miglior adattamento sul grafico registrato che su quello non registrato.
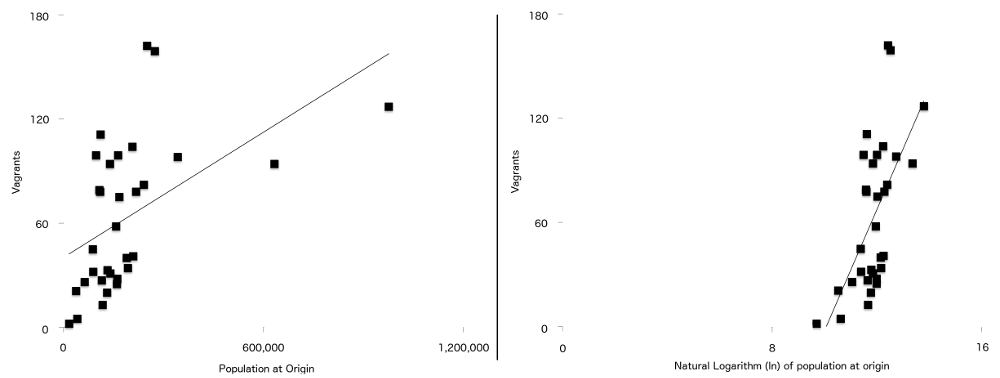
Figura 7: Numero di Vagabondi tracciati contro la popolazione all’origine (a sinistra) e registro naturale della popolazione di origine (a destra) con una semplice linea di regressione sovrapposta su entrambi. Si noti la relazione più forte tra le due variabili visibili sul secondo grafico.
Poiché questo è il caso di questi dati particolari (i tuoi dati in un tipo simile di studio potrebbero non seguire questo schema), la formula è stata regolata per utilizzare le versioni registrate naturalmente di queste due variabili, risultando nella formula finale utilizzata nel modello di gravità (Figura 8). Non avremmo potuto conoscere la necessità di questo aggiustamento fino a dopo aver raccolto i nostri dati variabili:
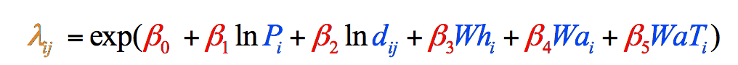
Figura 8: La formula finale del modello di gravità suddivisa per gradini e codificata per colore. Gli elementi in nero sono operazioni matematiche. Gli elementi in blu rappresentano le nostre variabili, che abbiamo appena raccolto (Passaggio 1). Gli elementi in rosso rappresentano le ponderazioni di ciascuna variabile, che dobbiamo calcolare (Fase 2), e l’elemento in arancione è la stima finale dei vagabondi di quella contea, che possiamo calcolare una volta che abbiamo le altre informazioni (Fase 3).
I valori nella Tabella 3 ci danno tutto il necessario per riempire le parti blu di ogni equazione in Figura 8. Ora possiamo rivolgere la nostra attenzione alle parti rosse, che ci dicono quanto sia importante ogni variabile nel modello complessivo, e ci dà i numeri di cui abbiamo bisogno per completare l’equazione.
Passaggio 2: Determinazione delle ponderazioni
Le ponderazioni per ogni variabile ci dicono quanto sia importante che il fattore push/pull sia relativo alle altre variabili quando si cerca di stimare il numero di vagabondi che dovrebbero provenire da una data contea. I parametri β β must devono essere determinati attraverso l’intero set di dati a partire dai dati noti. Con questi a portata di mano saremo in grado di confrontare le singole osservazioni specifiche di origine con il modello generale. Possiamo quindi esaminarli e identificare i flussi oltre e sotto previsti tra le varie origini e la destinazione.
In questa fase non sappiamo quanto sia importante ciascuno. Forse il prezzo del grano è un predittore migliore della migrazione rispetto alla distanza? Non lo sapremo fino a quando non calcoleremo i valori di β β1 through attraverso β β55 (le ponderazioni) risolvendo l’equazione sopra. L’intercetta y (β β0 possible) è possibile calcolare solo una volta che si conoscono tutti gli altri (β β1-β5 β). Questi sono i valori ROSSI in Figura 8 sopra. Le ponderazioni sono riportate nella tabella 4 e nella tabella A1 della carta originale.16 Ora dimostreremo come siamo arrivati a questi valori.
Per calcolare questi valori a mano lunga richiede una quantità incredibile di lavoro. Useremo una soluzione rapida nel linguaggio di programmazione R che sfrutta il pacchetto di massa di William Venables e Brian Ripley in grado di risolvere equazioni di regressione binomiale negative come il nostro modello di gravità con una singola riga di codice. Tuttavia, è importante capire i principi alla base di ciò che si sta facendo per apprezzare ciò che fa il codice (nota che le seguenti sezioni non fanno il calcolo, ma spiegano i suoi passi per te; faremo il calcolo con il codice più in basso nella pagina).
Calcolare i Singoli pesi (in linea di Principio)
$β_{1}$, $β_{2}$, ecc, sono le stesse come $β$ nel Semplice modello di Regressione Lineare di cui sopra, che è la pendenza della linea di regressione (l’aumento oltre la corsa, o quanto $y$ aumenta quando $x$ aumenta di 1). L’unica differenza qui tra una semplice regressione lineare e il nostro modello di gravità è che dobbiamo calcolare 5 pendenze invece di 1.
Una regressione lineare semplice\(y = α + ßx\)
Dovremo risolvere per ciascuna di queste cinque pendenze prima di poter calcolare l’intercetta y nel passaggio successivo. Questo perché le pendenze dei vari valori β β are fanno parte dell’equazione per calcolare l’intercetta y.
La formula per calcolare β β in in un’analisi di regressione è:
\
Coefficiente di correlazione di Pearson
Il coefficiente di correlazione di Pearson può essere calcolato a mano lunga, ma in questo caso è un calcolo piuttosto lungo, che richiede 64 numeri. Ci sono alcuni grandi video tutorial in inglese disponibili on-line, se volete vedere un walk-through di come fare i calcoli a mano lunga.17 Ci sono anche un certo numero di calcolatori online che calcoleranno r r for per te se fornisci i dati. Dato l’elevato numero di cifre da calcolare, consiglierei un sito Web con uno strumento integrato progettato per effettuare questo calcolo. Assicurati di scegliere un sito affidabile, come quello offerto da un’università.
Calcolare $s_{y}
La deviazione standard è un modo per esprimere la quantità di variazione rispetto alla media (media) presente nei dati. In altre parole, i dati sono abbastanza raggruppati attorno alla media o lo spread è molto più ampio?
Ancora una volta, ci sono calcolatrici online e pacchetti software statistici che possono fare questo calcolo per te se fornisci i dati.
Calcolo β β_{0}$ (l’intercetta y)
Successivamente, dobbiamo calcolare l’intercetta y. La formula per calcolare l’intercetta y in una regressione lineare semplice è:
\
Tuttavia, il calcolo diventa molto più complicato in un’analisi di regressione multipla, poiché ogni variabile influenza il calcolo. Questo rende molto difficile farlo a mano, ed è uno dei motivi per cui optiamo per una soluzione programmatica.
Il codice per calcolare le ponderazioni
Il pacchetto statistico di MASSA, scritto per il linguaggio di programmazione R, ha una funzione che può risolvere equazioni di regressione binomiale negative, rendendo molto facile calcolare quella che altrimenti sarebbe una formula a mano lunga molto difficile.
Questa sezione presuppone che sia stato installato R e sia stato installato il pacchetto MASS. Se non l’hai fatto dovrai prima di procedere. Tutorial di Taryn Dewar sulle basi R con dati tabulari include le istruzioni di installazione R.
Per utilizzare questo codice, è necessario scaricare una copia del set di dati delle cinque variabili più il numero di vagabondi osservati da ciascuna delle 32 contee. Questo è disponibile sopra come Tabella 3, o può essere scaricato come .file csv. Qualunque sia la modalità scelta, salva il file come VagrantsExampleData.csv. Se si utilizza un Mac assicurarsi di salvarlo come un formato di Windows .file csv. Apri VagrantsExampleData.csv e familiarizzare con i suoi contenuti. Dovresti notare ciascuna delle contee 32, insieme a ciascuna delle variabili che abbiamo discusso in questo tutorial. Useremo le intestazioni delle colonne per accedere a questi dati con il nostro programma per computer. Avrei potuto chiamare loro niente, ma in questo file sono:
vagrantspopulationdistancewheatwageswageTrajectory
nella stessa directory In cui è stato salvato il file csv, creare e salvare un nuovo R file di script (si può fare questo con qualsiasi editor di testo o con RStudio, ma non usare un word processor come microsoft Word). Salvalo come pesocalcoli.r.
Scriveremo ora un breve programma che:
- Installa il pacchetto di MASSA
- Chiama il pacchetto di MASSA in modo che possiamo usarlo nel nostro codice
- Memorizza il contenuto del .file csv per una variabile che possiamo usare a livello di codice
- Risolve l’equazione del modello di gravità utilizzando il set di dati
- Emette i risultati del calcolo.
Ciascuna di queste attività verrà eseguita a turno con una singola riga di codice
Copia il codice sopra riportato nei tuoi calcoli di ponderazione.r file e salva. Ora puoi eseguire il codice usando il tuo ambiente R preferito (io uso RStudio) e i risultati del calcolo dovrebbero apparire nella finestra della console (come appare dipenderà dal tuo ambiente). Potrebbe essere necessario impostare la directory di lavoro del proprio ambiente R nella directory contenente il proprio .csv e .file R. Se stai usando RStudio puoi farlo tramite i menu (Sessione – > Imposta Directory di lavoro- > Scegli Directory). Puoi anche ottenere lo stesso con il comando:
setwd(PATH) #change "PATH" to the full location on your computer where the files can be foundSi noti che la linea 4 è la linea che risolve l’equazione per noi, usando il glm.funzione nb, che è l’abbreviazione di “modello lineare generalizzato – binomio negativo”. Questa linea richiede un numero di ingressi:
- le nostre variabili utilizzando le intestazioni di colonna come scritto nel .file csv, insieme a qualsiasi registrazione che deve essere eseguita su di loro (
vagrants, log (population), log(distance),wheat,wages,wageTrajectory). Se si esegue un modello con i propri dati, è necessario modificarli per riflettere le intestazioni delle colonne nel set di dati. - dove il codice può trovare i dati – in questo caso una variabile che abbiamo definito nella riga 3 chiamata
gravityModelData.
Gli output del calcolo possono essere visti in Figura 9:
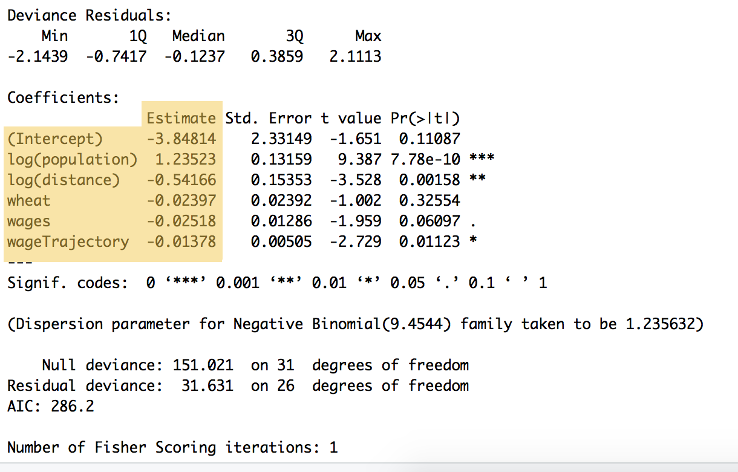
Figura 9: Il riepilogo del codice sopra riportato, che mostra le ponderazioni per ciascuna variabile e l’intercetta y, elencate nell’intestazione ” Stima “(da$\beta_{0} to a $ \ beta_ {5}$. Questa sintesi mostra anche una serie di altri calcoli, compresa la significatività statistica.
Fase 3: Calcolando le stime per ogni contea
Dobbiamo farlo una volta per ciascuna delle 32 contee.
Puoi farlo con una calcolatrice scientifica, creando una formula di foglio di calcolo o scrivendo un programma per computer. Per farlo automaticamente in R, puoi aggiungere quanto segue al tuo codice ed eseguire nuovamente il programma. Questo ciclo for calcola il numero previsto di vagabondi da ciascuna delle 32 contee nell’esempio e stampa i risultati per farti vedere:
Per costruire la comprensione, suggerisco di fare una contea a mano lunga. Questo tutorial utilizzerà Hertfordshire come esempio a mano lunga (ma il processo è esattamente lo stesso per le altre 31 contee).
Utilizzando i dati per Hertfordshire nella Tabella 3 e le ponderazioni per ogni variabile nella Tabella 4, ora possiamo completare la nostra formula, che darà il risultato di 95:
Per prima cosa, scambiamo i simboli per i numeri, presi dalle tabelle sopra menzionate.
Quindi, iniziare a calcolare i valori per arrivare alla stima. Ricordando l’ordine matematico delle operazioni, moltiplica i valori prima di aggiungerli. Così inizia calcolando ogni variabile (è possibile utilizzare una calcolatrice scientifica per questo):
Il passo successivo è quello di aggiungere i numeri insieme:
estimated vagrants = exp(4.56232408897)E, infine, di calcolare la funzione esponenziale (l’uso di una calcolatrice scientifica):
estimated vagrants = 95.8059926832Abbiamo eliminato il resto e ha dichiarato che la stima del numero di vagabondi da Hertfordshire in questo modello è di 95. È necessario condurre gli stessi calcoli per ciascuna delle altre contee, che si potrebbe accelerare utilizzando un programma di foglio di calcolo. Solo per essere sicuro di poterlo fare di nuovo, ho incluso anche i numeri per Buckinghamshire:
Hertfordshire
\
Buckinghamshire
\
Consiglio di scegliere un’altra contea e calcolarla a lungo prima di andare avanti, per assicurarti di poter fare i calcoli da solo. La risposta corretta è disponibile nella Tabella 5, che confronta i valori osservati (come visto nel record della sorgente primaria) con i valori stimati (come calcolati dal nostro modello di gravità). Il “Residuo” è la differenza tra i due, con una grande differenza che suggerisce un numero inaspettato di vagabondi che potrebbe valere la pena dare un’occhiata più da vicino con il cappello dello storico.
| Contea | Valore Osservato | Valore Stimato | Residua |
|---|---|---|---|
| Bedfordshire | 26 | 41 | -15 |
| Berkshire | 111 | 76 | 35 |
| Buckinghamshire | 79 | 83 | -4 |
| Cambridgeshire | 32 | 48 | -16 |
| Cheshire | 34 | 44 | -10 |
| Cornovaglia | 40 | 42 | -2 |
| Cumberland | 13 | 21 | -8 |
| Derbyshire | 28 | 36 | -8 |
| Devon | 98 | 121 | -23 |
| Dorset | 27 | 36 | -9 |
| Durham | 25 | 31 | -6 |
| Gloucestershire | 162 | 123 | 39 |
| Hampshire | 78 | 92 | -14 |
| Herefordshire | 45 | 39 | 6 |
| Hertfordshire | 99 | 95 | 4 |
| Huntingdonshire | 21 | 18 | 3 |
| Lancashire | 94 | 84 | 10 |
| Leicestershire | 20 | 28 | -8 |
| Lincolnshire | 41 | 86 | -45 |
| Northamptonshire | 33 | 78 | -45 |
| Northumberland | 58 | 29 | 29 |
| Novara | 31 | 28 | 3 |
| Oxfordshire | 78 | 52 | 26 |
| Rutland | 2 | 4 | -2 |
| Shropshire | 75 | 66 | 9 |
| Somerset | 159 | 145 | 14 |
| Staffordshire | 82 | 85 | -3 |
| Warwickshire | 104 | 70 | 34 |
| Westmorland | 5 | 5 | 0 |
| Wiltshire | 99 | 95 | 4 |
| Worcestershire | 94 | 53 | 41 |
| Yorkshire | 127 | 207 | -80 |
Passo 4 – Interpretazione Storica
In questa fase, il processo di modellizzazione è completa, e la fase finale è l’interpretazione storica.
L’articolo originale pubblicato su cui si è basato questo caso di studio, è dedicato principalmente a interpretare ciò che i risultati della modellazione significano per la nostra comprensione della migrazione di classe inferiore nel diciottesimo secolo. Come si vede nella mappa in Figura 5, c ” erano parti del paese che il modello fortemente suggerito erano o over – o under-invio di migranti di classe inferiore a Londra.
I coautori hanno offerto le loro interpretazioni sul motivo per cui questi modelli potrebbero essere apparsi. Queste interpretazioni variavano per luogo. Nelle aree del nord dell’Inghilterra che stavano rapidamente industrializzando, come lo Yorkshire o Manchester, le opportunità a livello locale sembravano dare alle persone meno motivi per andarsene, con conseguente migrazione inferiore al previsto a Londra. Nelle aree in declino ad ovest, come Bristol, il richiamo di Londra era più forte come sempre più persone hanno lasciato in cerca di lavoro nella capitale.
Non tutti i pattern erano previsti. Il Northumberland nell’estremo nord est si è rivelato un’anomalia regionale, inviando a Londra molti più migranti (donne) di quanti ci aspetteremmo di vedere. Senza le uscite del modello, è improbabile che avremmo pensato di considerare Northumberland a tutti, soprattutto perché era così lontano dalla Metropoli e abbiamo presunto avrebbe avuto legami deboli con Londra. Il modello ha quindi fornito nuove prove da considerare come storici e ha cambiato la nostra comprensione della relazione Londra-Northumberland. Una discussione completa dei nostri risultati può essere letta nell’articolo originale.18
Portare avanti le tue conoscenze
Dopo aver provato questo problema di esempio, dovresti avere una chiara comprensione di come utilizzare questa formula di esempio, nonché se un modello di gravità potrebbe essere una soluzione appropriata per il tuo problema di ricerca. Hai l’esperienza e il vocabolario per approcciare e discutere i modelli di gravità con un collaboratore adeguatamente alfabetizzato matematicamente, se necessario, che può aiutarti ad adattarlo al tuo caso di studio.
Se hai la fortuna di avere anche dati sui migranti che si trasferiscono a Londra di fine Settecento e vuoi modellarli usando le stesse cinque variabili sopra elencate, questa formula funzionerebbe così com’è-c’è uno studio facile qui per qualcuno con i dati giusti. Tuttavia, questo modello non funziona solo per gli studi sui migranti che si trasferiscono a Londra. Le variabili possono cambiare, e la destinazione non ha bisogno di essere Londra. Sarebbe possibile utilizzare un modello di gravità per studiare la migrazione verso l’antica Roma, o Bangkok del ventunesimo secolo, se si hanno i dati e la domanda di ricerca. Non ha nemmeno bisogno di essere un modello di migrazione. Per utilizzare il caso di studio del caffè colombiano dall’introduzione, che si concentra sul commercio piuttosto che sulla migrazione, la tabella 6 mostra un uso praticabile della stessa formula, inalterato.
| Criteri di | Caffè Esportazione Esempio |
|---|---|
| UN punto di origine | le esportazioni di caffè dal porto di Barranquilla, Colombia |
| PIÙ finito destinazioni | 21 paesi dell’Emisfero Occidentale in 1950 |
| CINQUE variabili esplicative | (1) numero di Oceano Atlantico porte nel paese ricevente (2) miglia dalla Colombia, (3) Prodotto interno Lordo del paese di ricezione, (4) Nazionale di Caffè coltivati in tonnellate, (5) negozi di caffè ogni 10.000 abitanti |
C’è una lunga storia di modelli di gravità in borsa di studio accademica. Per utilizzare uno in modo efficace per la ricerca, è necessario comprendere la teoria di base e la matematica dietro di loro e le ragioni che hanno sviluppato come hanno. È anche importante capire i loro limiti e le condizioni per usarli correttamente, alcuni dei quali sono stati discussi sopra. Potrebbe anche aiutare a sapere:
-
Un modello di gravità come quello utilizzato in questo esempio può funzionare solo in un sistema chiuso. Il modello di cui sopra aveva solo 32 possibili punti di origine, rendendo possibile eseguire il modello 32 volte. Un numero sconosciuto o infinitamente grande di punti di origine (o destinazioni a seconda del modello), richiederebbe un’equazione diversa.
-
Il concetto di modello di gravità si basa anche sulla premessa che i movimenti (migrazione, commercio, ecc.) si basano su una raccolta di decisioni individuali volontarie che potrebbero essere influenzate da fattori esterni, ma non sono interamente controllate da essi. Ad esempio, le migrazioni volontarie o gli acquisti di libero arbitrio potrebbero essere modellati utilizzando questa tecnica, ma la migrazione forzata, l’acquisto obbligatorio o processi naturali come la migrazione degli uccelli o il flusso fluviale potrebbero non seguire gli stessi principi e quindi potrebbe essere necessario un diverso tipo di modello.
-
I modelli di gravità possono essere utilizzati per prevedere il comportamento delle popolazioni ma non degli individui, e quindi i tentativi di modellare i dati dovrebbero includere un gran numero di movimenti per garantire la significatività statistica.
Ci sono molte altre insidie, ma anche enormi possibilità. È mia speranza che questo walk-through di un modello di gravità, e la sua ricerca pubblicata di accompagnamento, renderà questo potente strumento più accessibile per gli storici. Se avete intenzione di utilizzare un modello di gravità nella vostra ricerca accademica, l’autore consiglia vivamente i seguenti articoli:
Ringraziamenti
Con ringraziamenti ad Angela Kedgley, Sarah Lloyd, Tim Hitchcock, Joe Cozens, Katrina Navickas e Leanne Calvert per aver letto e commentato le prime bozze di questo articolo. Anche grazie alla British Academy per il finanziamento del laboratorio di scrittura a Bogotá, Colombia in cui questo articolo è stato redatto. E infine ad Adam Dennett per avermi introdotto a queste meravigliose formule e liberando il loro potenziale per gli storici.